The purpose of the study was to determine whether graph-based machine learning techniques, which have increased prevalence in the last few years, can accurately classify data into one of many clusters, while requiring less labeled training data and parameter tuning as opposed to traditional machine learning algorithms. The results determined that the accuracy of graph-based and traditional classification algorithms depends directly upon the number of features of each dataset, the number of classes in each dataset, and the amount of labeled training data used.
The authors looked at the ability of machine learning algorithms to interpret language given their increasing use in moderating content on social media. Using an explainable model they were able to achieve 81% accuracy in detecting fake vs. real news based on language of posts alone.
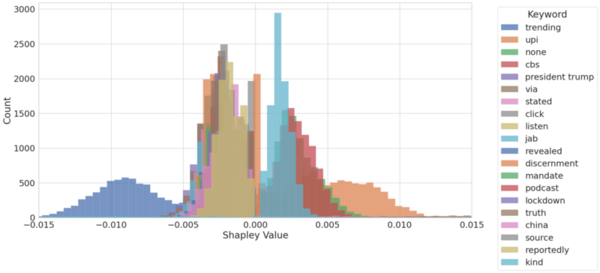
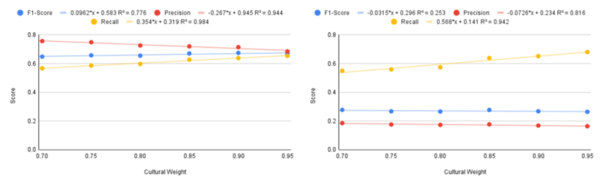
The authors develop a new method for training machine learning algorithms to differentiate between hate speech and cultural speech in online platforms.
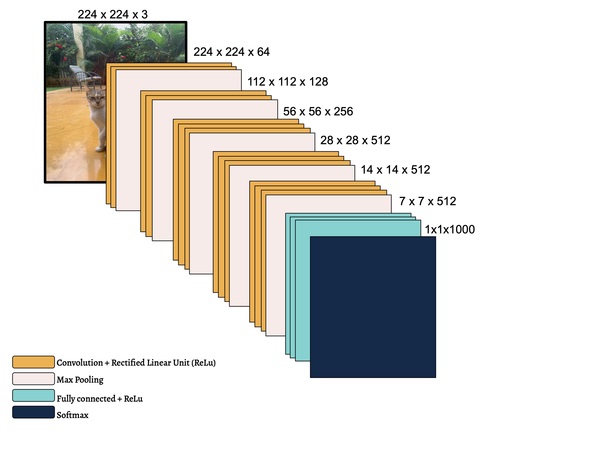
In this study, the authors seek to improve a machine learning algorithm used for image classification: identifying male and female images. In addition to fine-tuning the classification model, they investigate how accuracy is affected by their changes (an important task when developing and updating algorithms). To determine accuracy, a set of images is used to train the model and then a separate set of images is used for validation. They found that the validation accuracy was close to the training accuracy. This study contributes to the expanding areas of machine learning and its applications to image identification.
The diagnosis of malaria remains one of the major hurdles to eradicating the disease, especially among poorer populations. Here, the authors use machine learning to improve the accuracy of deep learning algorithms that automate the diagnosis of malaria using images of blood smears from patients, which could make diagnosis easier and faster for many.
In this study, the authors investigate the demographic indicators for voter shift between the 2016 and 2020 presidential elections based on demographic data put through a K-nearest neighbors classification algorithm and Principal Component Analysis.
In this study, we developed an algorithm to estimate the contact rate and the average infectious period of influenza using a Susceptible, Infected, and Recovered (SIR) epidemic model. The parameters in this model were estimated using data on infected Greek individuals collected from the National Public Health Organization. Our model labeled influenza as an epidemic with a basic reproduction value greater than one.
In the United States, there are currently 17.8 million affected by atopic dermatitis (AD), commonly known as eczema. It is characterized by itching and skin inflammation. AD patients are at higher risk for infections, depression, cancer, and suicide. Genetics, environment, and stress are some of the causes of the disease. With the rise of personalized medicine and the acceptance of gene-editing technologies, AD-related variations need to be identified for treatment. Genome-wide association studies (GWAS) have associated the Filaggrin (FLG) gene with AD but have not identified specific problematic single nucleotide polymorphisms (SNPs). This research aimed to refine known SNPs of FLG for gene editing technologies to establish a causal link between specific SNPs and the diseases and to target the polymorphisms. The research utilized R and its Bioconductor packages to refine data from the National Center for Biotechnology Information's (NCBI's) Variation Viewer. The algorithm filtered the dataset by coding regions and conserved domains. The algorithm also removed synonymous variations and treated non-synonymous, frameshift, and nonsense separately. The non-synonymous variations were refined and ordered by the BLOSUM62 substitution matrix. Overall, the analysis removed 96.65% of data, which was redundant or not the focus of the research and ordered the remaining relevant data by impact. The code for the project can also be repurposed as a tool for other diseases. The research can help solve GWAS's imprecise identification challenge. This research is the first step in providing the refined databases required for gene-editing treatment.
This study hypothesized that a machine learning model could accurately predict the severity of California wildfires and determine the most influential meteorological factors. It utilized a custom dataset with information from the World Weather Online API and a Kaggle dataset of wildfires in California from 2013-2020. The developed algorithms classified fires into seven categories with promising accuracy (around 55 percent). They found that higher temperatures, lower humidity, lower dew point, higher wind gusts, and higher wind speeds are the most significant contributors to the spread of a wildfire. This tool could vastly improve the efficiency and preparedness of firefighters as they deal with wildfires.