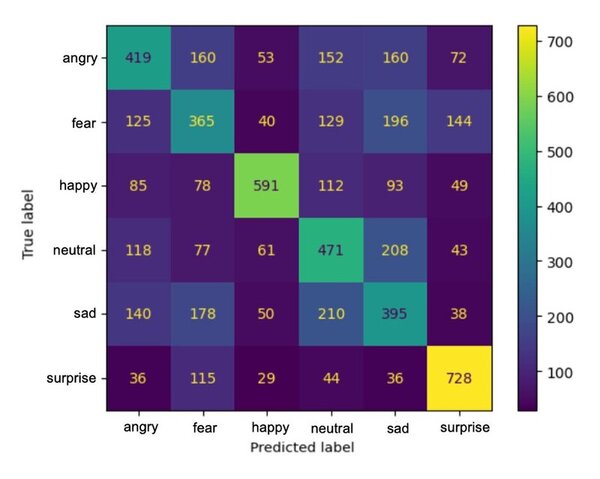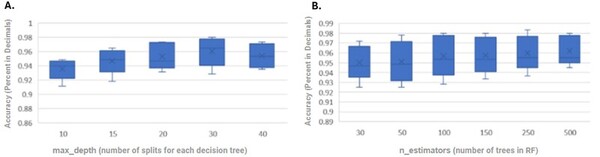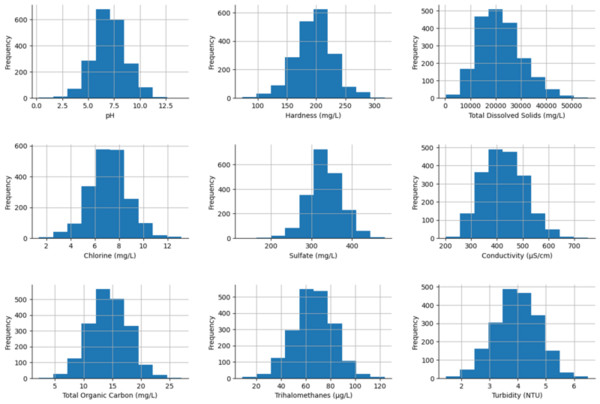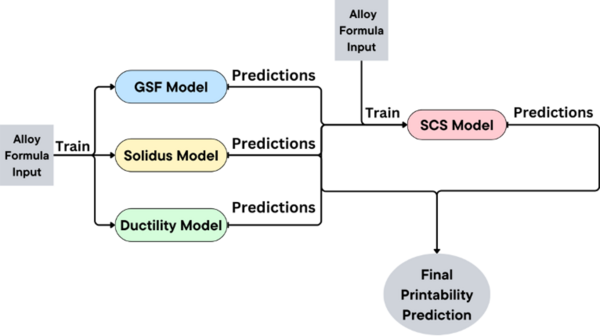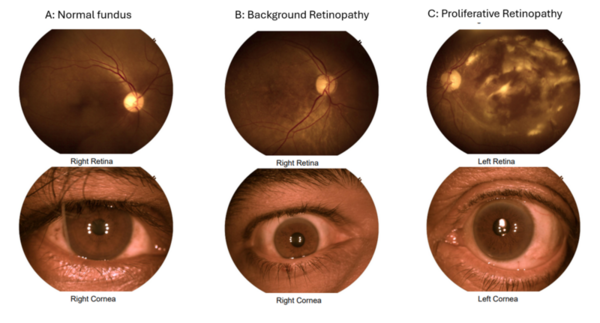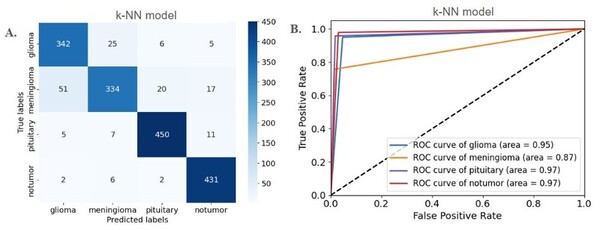
This manuscript explores the performance of five different machine learning models in classifying brain tumors from a dataset of MRI scans. The authors find that several of the models showed >90% accuracy. Thus, the authors suggest that machine learning models demonstrate potential for effective implementation in clinical settings, including as a diagnostic tool that can be used to complement the expertise of neuroradiologists.
Read More...