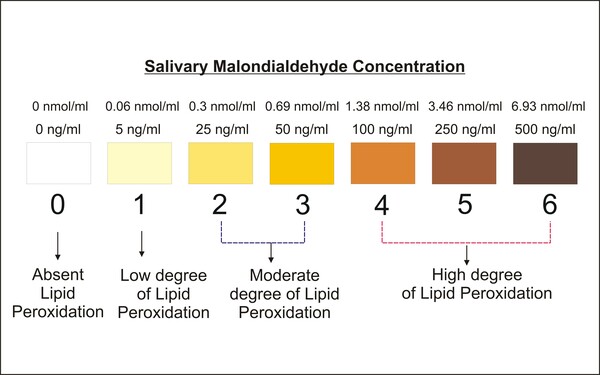
Smoking generates free radicals and reactive oxygen species which induce cell damage and lipid peroxidation. This is linked to the development of oral cancer in chronic smokers. The authors of this study developed Quitpuff, simple colorimetric test to measure the extent of lipid peroxidation in saliva samples. This test detected salivary lipid peroxidation with 96% accuracy in test subjects and could serve as an inexpensive, non-invasive test for smokers to measure degree of salivary lipid peroxidation and potential risk of oral cancer.
With advancements in machine learning a large data scale, high throughput virtual screening has become a more attractive method for screening drug candidates. This study compared the accuracy of molecular descriptors from two cheminformatics Mordred and PaDEL, software libraries, in characterizing the chemo-structural composition of 53 compounds from the non-nucleoside reverse transcriptase inhibitors (NNRTI) class. The classification model built with the filtered set of descriptors from Mordred was superior to the model using PaDEL descriptors. This approach can accelerate the identification of hit compounds and improve the efficiency of the drug discovery pipeline.
The electronic health record (EHR), along with its mobile application, has demonstrated the ability to improve the efficiency and accuracy of health care delivery. This study included data from 874 health care providers over a 12-month period regarding their usage of mobile phone (EPIC® Haiku) and tablet (EPIC® Canto) mEHR. Ambulatory and inpatient care providers had the greatest usage levels over the 12-month period. Awareness of workflow allows for optimization of mEHR design and implementation, which should increase mEHR adoption and usage, leading to better health outcomes for patients.
This study hypothesized that a machine learning model could accurately predict the severity of California wildfires and determine the most influential meteorological factors. It utilized a custom dataset with information from the World Weather Online API and a Kaggle dataset of wildfires in California from 2013-2020. The developed algorithms classified fires into seven categories with promising accuracy (around 55 percent). They found that higher temperatures, lower humidity, lower dew point, higher wind gusts, and higher wind speeds are the most significant contributors to the spread of a wildfire. This tool could vastly improve the efficiency and preparedness of firefighters as they deal with wildfires.
Auto-Regressive Integrated Moving Average (ARIMA) models are known for their influence and application on time series data. This statistical analysis model uses time series data to depict future trends or values: a key contributor to crime mapping algorithms. However, the models may not function to their true potential when analyzing data with many different patterns. In order to determine the potential of ARIMA models, our research will test the model on irregularities in the data. Our team hypothesizes that the ARIMA model will be able to adapt to the different irregularities in the data that do not correspond to a certain trend or pattern. Using crime theft data and an ARIMA model, we determined the results of the ARIMA model’s forecast and how the accuracy differed on different days with irregularities in crime.
Every year, around 40% of undergraduate students in the United States discontinue their studies, resulting in a loss of valuable education for students and a loss of money for colleges. Even so, colleges across the nation struggle to discover the underlying causes of these high dropout rates. In this paper, the authors discuss the use of machine learning to find correlations between the built environment factors and the retention rates of colleges. They hypothesized that one way for colleges to improve their retention rates could be to improve the physical characteristics of their campus to be more pleasing. The authors used image classification techniques to look at images of colleges and correlate certain features like colors, cars, and people to higher or lower retention rates. With three possible options of high, medium, and low retention rates, the probability that their models reached the right conclusion if they simply chose randomly was 33%. After finding that this 33%, or 0.33 mark, always fell outside of the 99% confidence intervals built around their models’ accuracies, the authors concluded that their machine learning techniques can be used to find correlations between certain environmental factors and retention rates.
Osteosarcoma is a type of bone cancer that affects young adults and children. Early diagnosis of osteosarcoma is crucial to successful treatment. The current methods of diagnosis, which include imaging tests and biopsy, are time consuming and prone to human error. Hence, we used deep learning to extract patterns and detect osteosarcoma from histological images. We hypothesized that the combination of two different technologies (transfer learning and data augmentation) would improve the efficacy of osteosarcoma detection in histological images. The dataset used for the study consisted of histological images for osteosarcoma and was quite imbalanced as it contained very few images with tumors. Since transfer learning uses existing knowledge for the purpose of classification and detection, we hypothesized it would be proficient on such an imbalanced dataset. To further improve our learning, we used data augmentation to include variations in the dataset. We further evaluated the efficacy of different convolutional neural network models on this task. We obtained an accuracy of 91.18% using the transfer learning model MobileNetV2 as the base model with various geometric transformations, outperforming the state-of-the-art convolutional neural network based approach.
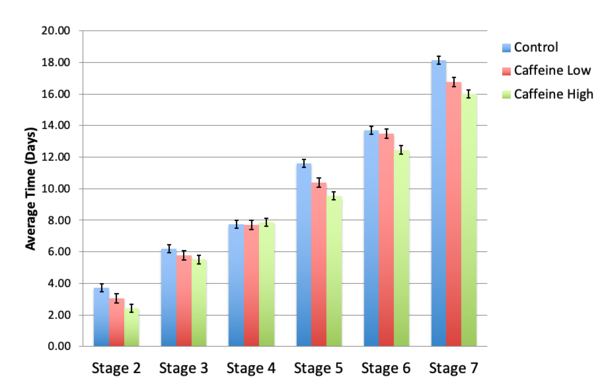
The degeneration of nerve cells in the brain can lead to pathologies such as Parkinson’s disease. It has been suggested that neurons in humans may regenerate. In this study, the effect of different doses of caffeine on regeneration was explored in the planeria model. Caffeine has been shown to enhance dopamine production, and dopamine is found in high concentrations in regenerating planeria tissues. Higher doses of caffeine accelerated planeria regeneration following decapitation, indicating a potential role for caffeine as a treatment to stimulate regeneration.
In South Asian countries, the major cause of oral cancer is reported to be chewing paan, which is comprised of betel leaf daubed with slaked lime paste and areca nut. To investigate how paan may contribute to the onset of cancer, the authors treated two immortalized cell lines with extracts of betel leaf, areca nut, and lime and evaluated how these treatments affected cell proliferation and cell death. Initial results indicate that while betel leaf alone may inhibit cell growth, areca nut promoted cancer cell survival and proliferation, even when co-treated with betel leaf. These data suggest that areca nut could exacerbate the progression of oral cancer in humans.
Many cases of viral hepatitis are easily preventable if caught early; however, a lack of public awareness regarding often leads to diagnoses near the final stages of disease when it is most lethal. Thus, we wanted to understand to what extent an individual's sex, age, education and country of residence (India or Singapore) impacts disease identification. We sent out a survey and quiz to residents in India (n = 239) and Singapore (n = 130) with questions that test their knowledge and awareness of the disease. We hypothesized that older and more educated individuals would score higher because they are more experienced, but that the Indian population will not be as knowledgeable as the Singaporean population because they do not have as many resources, such as socioeconomic access to schools and accessibility to healthcare, available to them. Additionally, we predicted that there would not be any notable differences between make and females. The results revealed that the accuracy for all groups we looked at was primarily below 50%, demonstrating a severe knowledge gap. Therefore, we concluded that if more medical professionals discussed viral hepatitis during hospital visits and in schools, patients can avoid the end stages of the disease in notable cases.