Development of a novel machine learning platform to identify structural trends among NNRTI HIV-1 reverse transcriptase inhibitors
(1) Amador Valley High School, Pleasanton, California; equal first authors, (2) Dublin High School, Dublin, California; equal first authors, (3) Leigh High School, San Jose, California; equal second authors, (4) Amador Valley High School, Pleasanton, California; equal second authors, (5) Milpitas High School, Milpitas, California; equal second authors, (6) BASIS Independent Silicon Valley, San Jose, California, (7) James Logan High School, Union City, California, (8) Bentley School, Lafayette, California, (9) Dept. of Computer Science & Engineering, Aspiring Scholars Directed Research Program, Fremont, California, (10) Dept. of Chemistry, Biochemistry, & Physics, Aspiring Scholars Directed Research Program, Fremont, California
https://doi.org/10.59720/21-098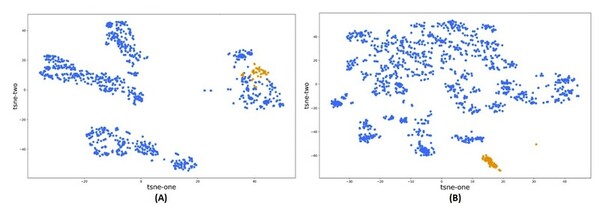
With advancements in machine learning powered by on-demand computing and information processing at a large data scale, high throughput virtual screening has become a more attractive method for screening drug candidates, reducing both costs and the timeframe from hit-to-lead. The efficiency of fingerprinting using cheminformatics-based approaches coupled with machine learning to model and identify structure-activity relationships (SAR) has immense potential to improve the time-to-market for the drug development process. This study compared the accuracy of molecular descriptors from two cheminformatics Mordred and PaDEL, software libraries, in characterizing the chemo-structural composition of 53 compounds from the non-nucleoside reverse transcriptase inhibitors (NNRTI) class. We built a logistic regression model to classify NNRTIs based on salient descriptors from each software. We hypothesized that the descriptor data generated by Mordred would be more accurate when characterizing the SAR between NNRTI compounds and the HIV-1 RT enzyme. We identified structural trends in potential inhibitors of the HIV-1 RT enzyme. The classification model built with the filtered set of descriptors from Mordred was superior to the model using PaDEL descriptors as it revealed significant cluster separation between the 53 NNRTI molecules and other drugs, while the filtered PaDEL descriptors model did not show a clear distinction between classes. This approach can accelerate the identification of hit compounds and improve the efficiency of the drug discovery pipeline.
This article has been tagged with: