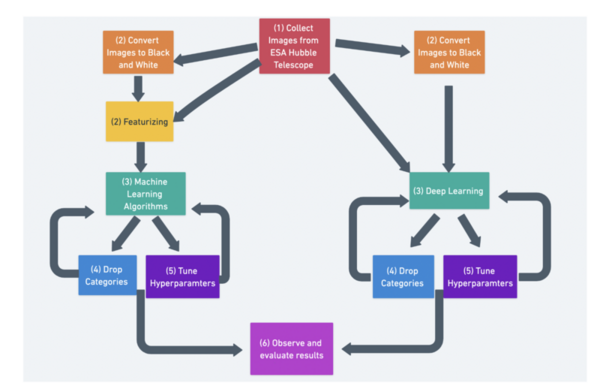
There are believed to be ~20,000 nebulae in the Milky Way Galaxy. However, humans have only cataloged ~1,800 of them even though we have gathered 1.3 million nebula images. Classification of nebulae is important as it helps scientists understand the chemical composition of a nebula which in turn helps them understand the material of the original star. Our research on nebulae classification aims to make the process of classifying new nebulae faster and more accurate using a hybrid of deep learning and machine learning techniques.
Researchers query whether reading comprehension is the same, worse, or better when using e-books as compared with standard paper texts. This study evaluated this question in the elementary school population. Our hypothesis was that information would be retained equally whether read from paper or from an electronic device. Each participant read four stories, alternating between electronic and paper media types. After each reading, the participants completed a five-question test covering the information read. The study participants correctly answered 167 out of 200 comprehension questions when reading from an electronic device. These same participants correctly answered 145 out of 200 comprehension questions when reading from paper. At a significance level of p < 0.05, the results showed that there was a statistically significant difference in reading comprehension between the two media, demonstrating better comprehension when using electronic media. The unexpected results of this study demonstrate a shift in children’s performance and desirability of using electronic media as a reading source.
Cancer is often caused by improper function of a few proteins, and sometimes it takes only a few proteins to malfunction to cause drastic changes in cells. Here the authors look at the genes that were mutated in patients with a type of pancreatic cancer to identify proteins that are important in causing cancer. They also determined which proteins currently lack effective treatment, and suggest that certain proteins (named KRAS, CDKN2A, and RBBP8) are the most important candidates for developing drugs to treat pancreatic cancer.
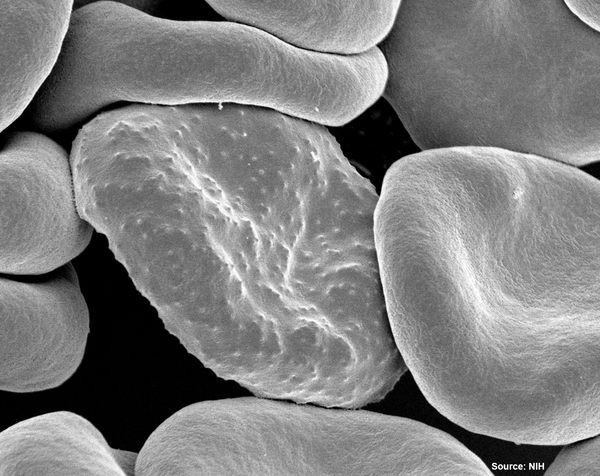
The diagnosis of malaria remains one of the major hurdles to eradicating the disease, especially among poorer populations. Here, the authors use machine learning to improve the accuracy of deep learning algorithms that automate the diagnosis of malaria using images of blood smears from patients, which could make diagnosis easier and faster for many.
Here, the authors investigated methods to reduce noise in audio composed of real-word sounds. They specifically used two spectral subtraction noise reduction algorithms: stationary and non-stationary finding notable differences in noise improvements depending on the noise sources.
Semantic segmentation - labelling each pixel in an image to a specific class- models require large amounts of manually labeled and collected data to train.
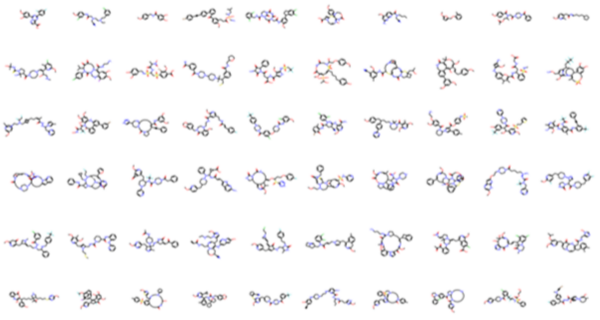
The authors investigate the ability of machine learning models to developing new drug-like molecules by learning desired chemical properties versus simply generating molecules that similar to those in the training set.
Seeking to investigate the effects of ambient pollutants on human respiratory health, here the authors used machine learning to examine asthma in Lost Angeles County, an area with substantial pollution. By using machine learning models and classification techniques, the authors identified that nitrogen dioxide and ozone levels were significantly correlated with asthma hospitalizations. Based on an identified seasonal surge in asthma hospitalizations, the authors suggest future directions to improve machine learning modeling to investigate these relationships.
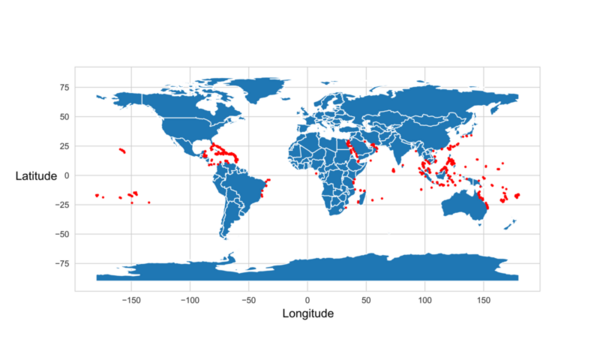
Coral bleaching is a fatal process that reduces coral diversity, leads to habitat loss for marine organisms, and is a symptom of climate change. This process occurs when corals expel their symbiotic dinoflagellates, algae that photosynthesize within coral tissue providing corals with glucose. Restoration efforts have attempted to repair damaged reefs; however, there are over 360,000 square miles of coral reefs worldwide, making it challenging to target conservation efforts. Thus, predicting the likelihood of bleaching in a certain region would make it easier to allocate resources for conservation efforts. We developed a machine learning model to predict global locations at risk for coral bleaching. Data obtained from the Biological and Chemical Oceanography Data Management Office consisted of various coral bleaching events and the parameters under which the bleaching occurred. Sea surface temperature, sea surface temperature anomalies, longitude, latitude, and coral depth below the surface were the features found to be most correlated to coral bleaching. Thirty-nine machine learning models were tested to determine which one most accurately used the parameters of interest to predict the percentage of corals that would be bleached. A random forest regressor model with an R-squared value of 0.25 and a root mean squared error value of 7.91 was determined to be the best model for predicting coral bleaching. In the end, the random model had a 96% accuracy in predicting the percentage of corals that would be bleached. This prediction system can make it easier for researchers and conservationists to identify coral bleaching hotspots and properly allocate resources to prevent or mitigate bleaching events.
Osteosarcoma is a type of bone cancer that affects young adults and children. Early diagnosis of osteosarcoma is crucial to successful treatment. The current methods of diagnosis, which include imaging tests and biopsy, are time consuming and prone to human error. Hence, we used deep learning to extract patterns and detect osteosarcoma from histological images. We hypothesized that the combination of two different technologies (transfer learning and data augmentation) would improve the efficacy of osteosarcoma detection in histological images. The dataset used for the study consisted of histological images for osteosarcoma and was quite imbalanced as it contained very few images with tumors. Since transfer learning uses existing knowledge for the purpose of classification and detection, we hypothesized it would be proficient on such an imbalanced dataset. To further improve our learning, we used data augmentation to include variations in the dataset. We further evaluated the efficacy of different convolutional neural network models on this task. We obtained an accuracy of 91.18% using the transfer learning model MobileNetV2 as the base model with various geometric transformations, outperforming the state-of-the-art convolutional neural network based approach.