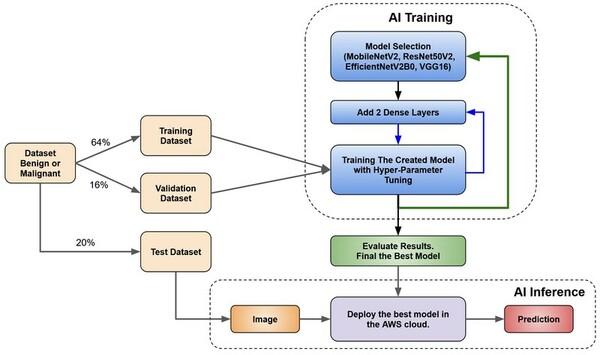
Skin cancer is a common and potentially deadly form of cancer. This study’s purpose was to develop an automated approach for early detection for skin cancer. We hypothesized that convolutional neural network-based models using transfer learning could accurately differentiate between benign and malignant moles using natural images of human skin.
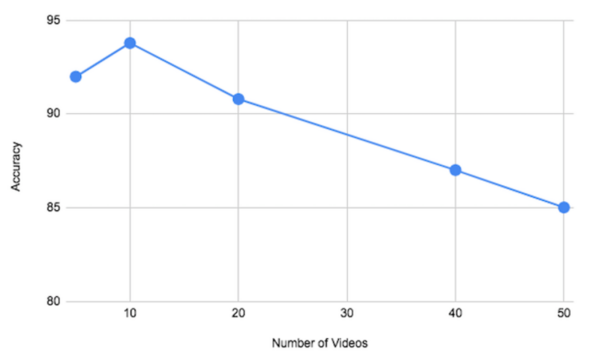
The Tor network allows individuals to secure their online identities by encrypting their traffic, however it is vulnerable to fingerprinting attacks that threaten users' online privacy. In this paper, the authors develop a new video fingerprinting model to explore how well video streaming can be fingerprinted in Tor. They found that their model could distinguish which one of 50 videos a user was hypothetically watching on the Tor network with 85% accuracy, demonstrating that video fingerprinting is a serious threat to the privacy of Tor users.
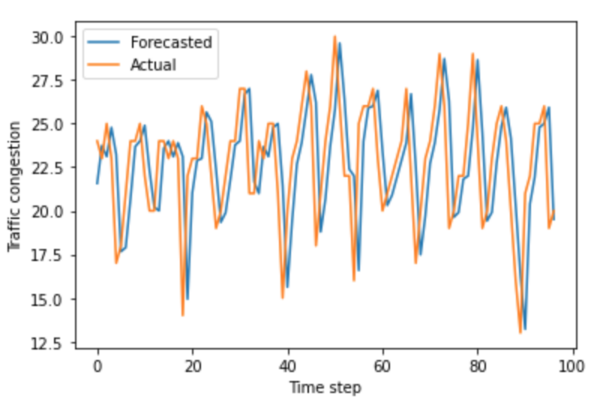
In this paper, we measured the privacy budgets and utilities of different differentially private mechanisms combined with different machine learning models that forecast traffic congestion at future timestamps. We expected the ANNs combined with the Staircase mechanism to perform the best with every value in the privacy budget range, especially with the medium high values of the privacy budget. In this study, we used the Autoregressive Integrated Moving Average (ARIMA) and neural network models to forecast and then added differentially private Laplacian, Gaussian, and Staircase noise to our datasets. We tested two real traffic congestion datasets, experimented with the different models, and examined their utility for different privacy budgets. We found that a favorable combination for this application was neural networks with the Staircase mechanism. Our findings identify the optimal models when dealing with tricky time series forecasting and can be used in non-traffic applications like disease tracking and population growth.
In this study, the authors test whether a gravity vehicle, which is a vehicle powered by its own gravity on a ramp, could be designed to move faster when mathematical calculations for optimal mass and center of gravity were applied in the design.
In this article, the authors propose an effective, environmentally-friendly method of producing conductive ink using expired waste oil, polystyrene, and graphene.
Middle school math forms the basis for advanced mathematical courses leading up to the university level. Large language models (LLMs) have the potential to power next-generation educational technologies, acting as digital tutors to students. The main objective of this study was to determine whether LLMs like ChatGPT, Bard, and Llama 2 can serve as reliable middle school math tutoring assistants on three tutoring tasks: hint generation, comprehensive solution, and exercise creation.
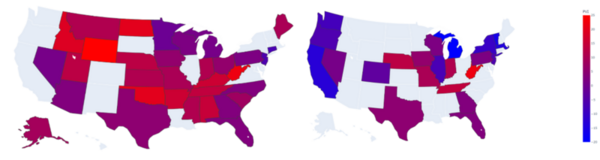
In this study, the authors investigate the demographic indicators for voter shift between the 2016 and 2020 presidential elections based on demographic data put through a K-nearest neighbors classification algorithm and Principal Component Analysis.
We systematically evaluated the effects of raw material composition, heat treatment, and mechanical properties on 13-8PH stainless steel alloy. The results of the neural network models were in agreement with experimental results and aided in the evaluation of the effects of aging temperature on double shear strength. The data suggests that this model can be used to determine the appropriate 13-8PH alloy aging temperature needed to achieve the desired mechanical properties, eliminating the need for many costly trials and errors through re-heat treatments.
The authors analyze political endorsement patterns and impacts from the 2018 and 2020 midterm elections and find that such endorsements may be predictable based on the ideological and demographic factors of the endorser.
With the advance of technology, artificial intelligence (AI) is now applied widely in society. In the study of AI, machine learning (ML) is a subfield in which a machine learns to be better at performing certain tasks through experience. This work focuses on the convolutional neural network (CNN), a framework of ML, applied to an image classification task. Specifically, we analyzed the performance of the CNN as the type of neural activation function changes.