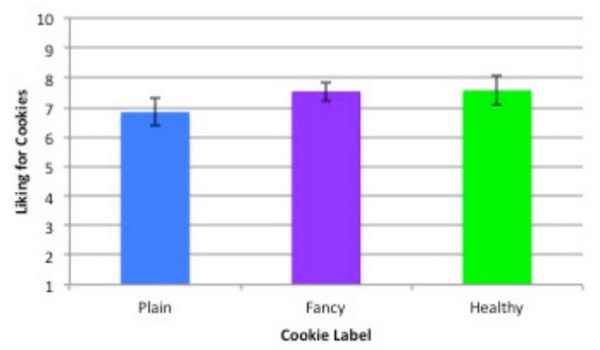
Previous studies have found that how a food item is labeled may influence people's liking of it. This study used a cookie taste test to investigate whether people's liking of a dessert item would be swayed by the use of different labels.
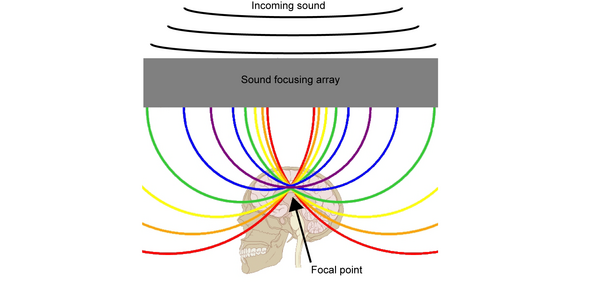
Sound waves can be amazingly powerful, especially when they work together. Here the authors create an “acoustic lens” that focuses sound waves on a single location. This makes the sound waves very powerful, capable of causing damage at a precise point. In the future, acoustic lenses like this could potentially be used to treat cancer by killing small tumors without surgery.
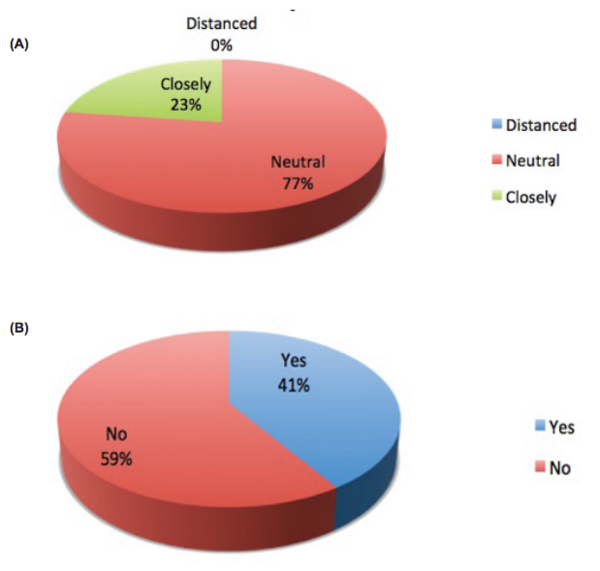
Racial inequality has been a major issue throughout the history of the United States. In recent years, however, especially with the election of America's first black president, many have claimed that we have made progress and are moving towards a post-racial society. The authors of this study sought to test that claim by evaluating whether high school age students still experience a phenomenon known as white guilt. White guilt is defined as remorse or shame felt by people of Caucasian descent about racial inequality.
Many of us take our vision for granted, but rarely do we measure how well we can see. In this study, the authors investigate the ability of people of different ages to read progressively fainter letters in dark light. They find that the ability to see in dim light drops drastically after age 30. The ability to read fainter letters worsens after age 30 as well. These findings should help inform lighting decisions everywhere from restaurants to road signs.
Rising atmospheric carbon dioxide levels are projected to lead to a 0.3- 0.4 unit decrease in ocean surface pH levels over the next century. In this study, the authors investigate the effect of pH change on the mass of calcified exoskeletons of common aquatic organisms found in South Florida coastal waters.
Polylactic acid (PLA) is a bio-based, compostable plastic that is comparable in cost to petroleum-based plastics. This study aims to evaluate the effects of UV treatment and mechanical chopping on the degradation of PLA. Based on their findings, the authors propose an alternative PLA degradation process that may be more time and energy efficient than current processes.
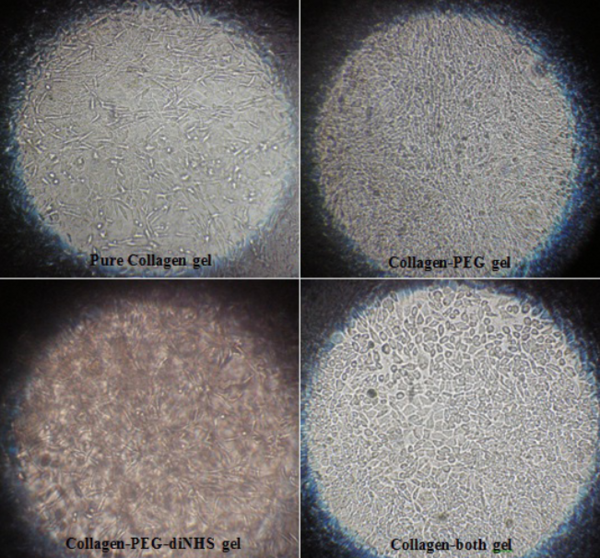
Environment affects the progression of life, especially at the cellular level. This study investigates multiple 3-dimensional growth environments, also known as scaffolds or hydrogels, and their effect on the growth of a type of cells called fibroblasts. These results suggest that a scaffold made of collagen and polyethylene glycol are favorable for cell growth. This research is useful for developing implantable devices to aid wound healing.
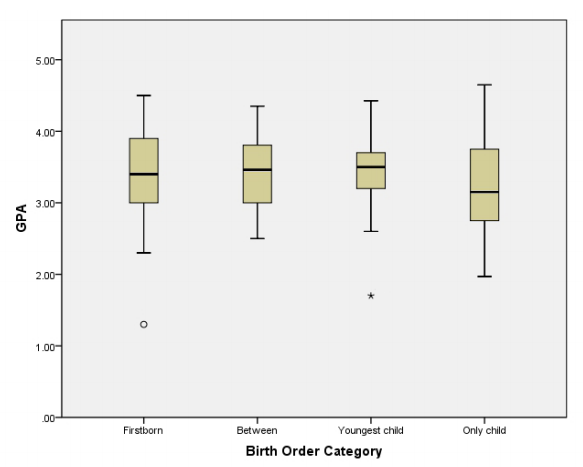
In many cultures and for many centuries, the implications of birth order have been examined. Birth order has been shown to affect personality, accomplishments, and even career choice. This study investigated the impact of birth order and ethnicity on two measures of academic success in high school: a student’s grade point average (GPA) and the number of Advanced Placement (AP) classes he or she took.
Here the authors introduce pressing filtration as a novel, efficient, and low-energy method for extracting dietary fiber from cabbage, which successfully retains heat-sensitive nutrients and achieves a high fiber yield. The study demonstrates the scalability and economic viability of this technique for commercial use, highlighting that the resulting high-fiber cabbage powder can be incorporated into familiar foods like hamburger buns and beef patties without compromising taste or sensory quality.
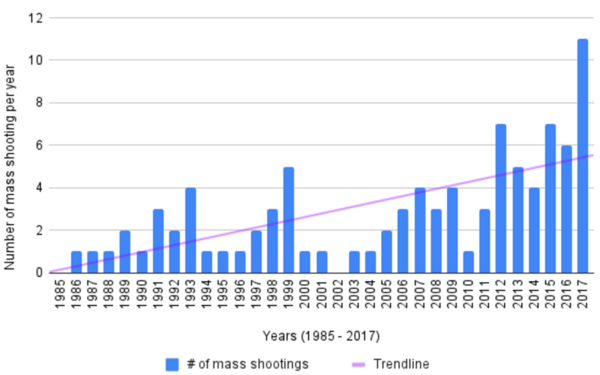
Researching gun violence and mass shootings in the U.S. is difficult due to the lack of consistent data collection. Some studies have linked mass shootings to personal financial stress, but little formal research exists on the impact of broader economic conditions. This study hypothesized an inverse relationship between mass shootings and economic performance, using the S&P 500 and unemployment rate as indicators.