Here, the authors investigated the most efficient way to position magnets to hold the most pieces of paper on the surface of a refrigerator. They used a regression model along with an artificial neural network to identify the most efficient positions of four magnets to be at the vertices of a rectangle.
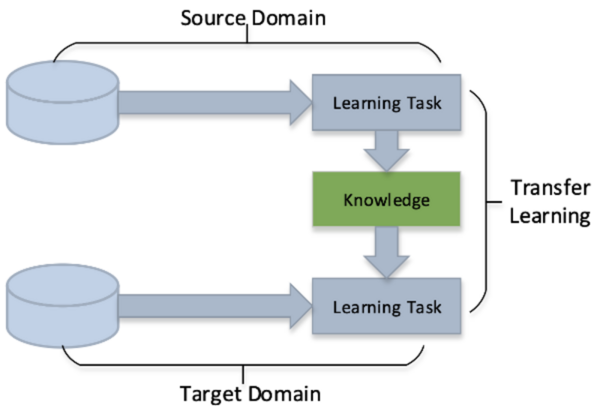
Based on the success of deep learning, recent works have attempted to develop a waste classification model using deep neural networks. This work presents federated learning (FL) for a solution, as it allows participants to aid in training the model using their own data. Results showed that with less clients, having a higher participation ratio resulted in less accuracy degradation by the data heterogeneity.
Osteosarcoma is a type of bone cancer that affects young adults and children. Early diagnosis of osteosarcoma is crucial to successful treatment. The current methods of diagnosis, which include imaging tests and biopsy, are time consuming and prone to human error. Hence, we used deep learning to extract patterns and detect osteosarcoma from histological images. We hypothesized that the combination of two different technologies (transfer learning and data augmentation) would improve the efficacy of osteosarcoma detection in histological images. The dataset used for the study consisted of histological images for osteosarcoma and was quite imbalanced as it contained very few images with tumors. Since transfer learning uses existing knowledge for the purpose of classification and detection, we hypothesized it would be proficient on such an imbalanced dataset. To further improve our learning, we used data augmentation to include variations in the dataset. We further evaluated the efficacy of different convolutional neural network models on this task. We obtained an accuracy of 91.18% using the transfer learning model MobileNetV2 as the base model with various geometric transformations, outperforming the state-of-the-art convolutional neural network based approach.
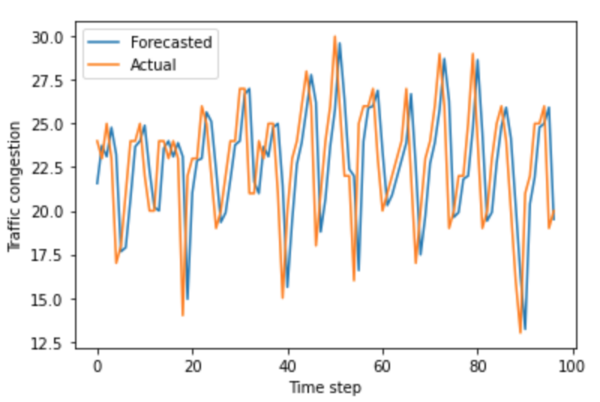
In this paper, we measured the privacy budgets and utilities of different differentially private mechanisms combined with different machine learning models that forecast traffic congestion at future timestamps. We expected the ANNs combined with the Staircase mechanism to perform the best with every value in the privacy budget range, especially with the medium high values of the privacy budget. In this study, we used the Autoregressive Integrated Moving Average (ARIMA) and neural network models to forecast and then added differentially private Laplacian, Gaussian, and Staircase noise to our datasets. We tested two real traffic congestion datasets, experimented with the different models, and examined their utility for different privacy budgets. We found that a favorable combination for this application was neural networks with the Staircase mechanism. Our findings identify the optimal models when dealing with tricky time series forecasting and can be used in non-traffic applications like disease tracking and population growth.
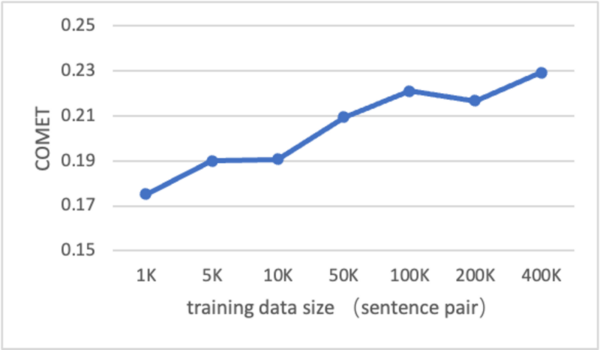
Machine translation remains a challenging area in artificial intelligence, with neural machine translation (NMT) making significant strides over the past decade but still facing hurdles, particularly in translation quality due to the reliance on expensive bilingual training data. This study explores whether large language models (LLMs), like GPT-4, can be effectively adapted for translation tasks and outperform traditional NMT systems.
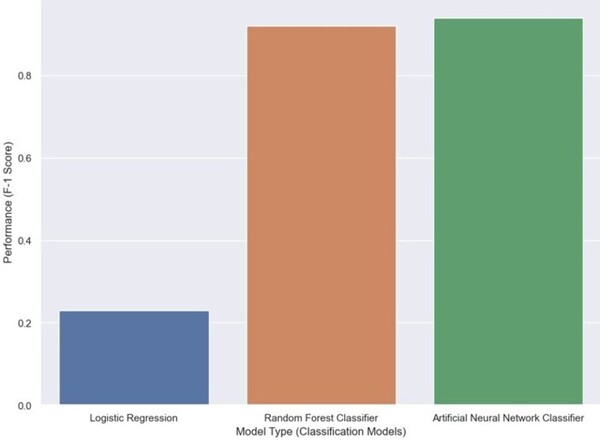
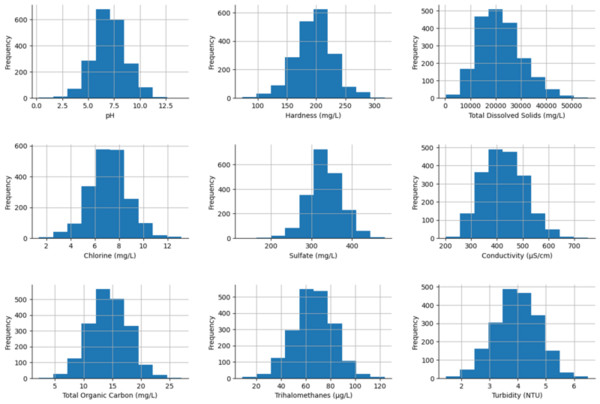
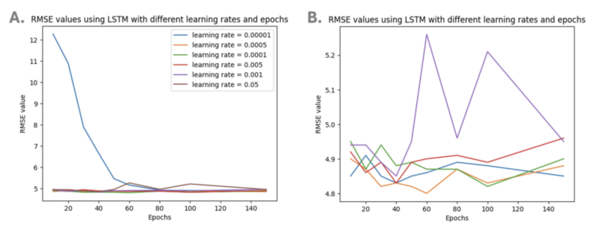
The global issue of water quality has led to the use of machine learning models, like ANN and SVM, to predict water potability. However, these models can be complex and resource-intensive. This research aimed to find a simpler, more efficient model for water quality prediction.
People with Type One diabetes often rely on Continuous Blood Glucose Monitors (CGMs) to track their blood glucose and manage their condition. Researchers are now working to help people with Type One diabetes more easily monitor their health by developing models that will future blood glucose levels based on CGM readings. Jalla and Ghanta tackle this issue by exploring the use of AI models to forecast blood glucose levels with CGM data.
Here the authors sought to use three machine learning models to predict poverty levels in Cambodia based on available household data. They found teat multilayer perceptron outperformed the other models, with an accuracy of 87 %. They suggest that data-driven approaches such as these could be used more effectively target and alleviate poverty.