Microscopic beauty is hiding in common kitchen ingredients - even vanillin flavoring can be turned into mesmerizing artwork by crystallizing the vanillin and examining it under a polarizing microscope. Wang and Pang explore this hidden beauty by determining the optimal conditions to grow crystalline vanillin films and by creating computer simulations of chemical interactions between vanillin molecules.
Here, the authors sought to investigate the effects of water current on the growth of colonies of duckweed, a floating plant that forms colonies in silent ponds, marshes, lakes , and streams in North America. They found that current flow mediates the formation of colonies, disrupting and recreating the colonies which provides the opportunity for reorganizations that were identified as beneficial.
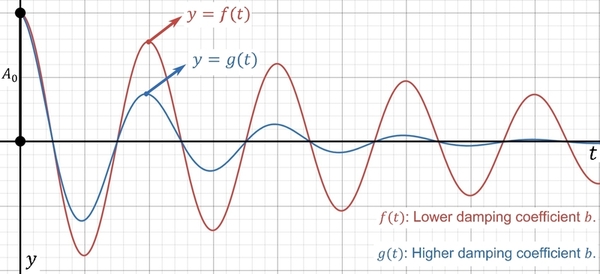
Dynamic viscosity is a quantity that describes the magnitude of a fluid’s internal friction or thickness. Traditionally, scientists measure this quantity by either calculating the terminal velocity of a falling sphere or the time a liquid takes to flow through a capillary tube. However, they have yet to conduct much research on finding this quantity through viscous damped simple harmonic motion. The present study hypothesized that the relationship between the dynamic viscosity and the damping coefficient is positively correlated.
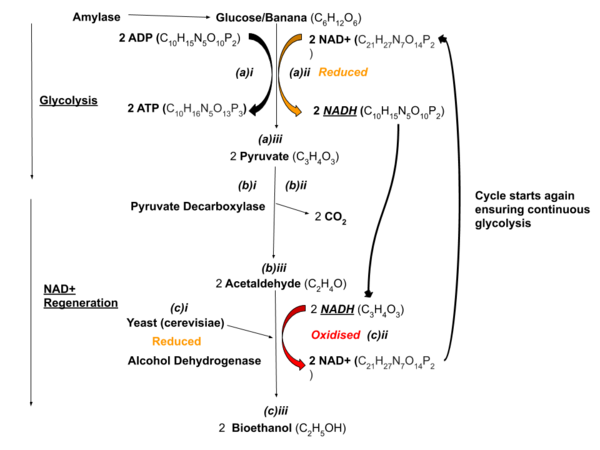
The authors investigate whether amylase or yeast had a more prominent role in determining the bioethanol concentration and bioethanol yield of banana samples. They hypothesized that amylase would have the most significant impact on the bioethanol yield and concentration of the samples. They found that while yeast is an essential component for producing bioethanol, the proportion of amylase supplied through a joint amylase-yeast mixture has a more significant impact on the bioethanol yield. This study provides a greater understanding of the mechanisms and implications involved in enzyme-based biofuel production, specifically of those pertaining to amylase and yeast.
Zebra mussels are an aquatic invasive species. They attach to essential industrial structures and harm the native ecosystem, costing millions of dollars each year to control. This study explored the effectiveness of two nontoxic materials (Sharklet & Netminder) in combating zebra mussel attachment.
The authors here investigate the absorbency of two leading brands of diapers. They find that Huggies Little Snugglers absorb over 50% more salt water than Pampers Swaddlers, although both absorb significantly more fluid than what an average newborn can produce.
The mountain chain of the Western Ghats on the Indian peninsula, a UNESCO World Heritage site, is home to about 200 frog species, 89 of which are endemic. Distinctive to each frog species, their vocalizations can be used for species recognition. Manually surveying frogs at night during the rain in elephant and big cat forests is difficult, so being able to autonomously record ambient soundscapes and identify species is essential. An effective machine learning (ML) species classifier requires substantial training data from this area. The goal of this study was to assess data augmentation techniques on a dataset of frog vocalizations from this region, which has a minimal number of audio recordings per species. Consequently, enhancing an ML model’s performance with limited data is necessary. We analyzed the effects of four data augmentation techniques (Time Shifting, Noise Injection, Spectral Augmentation, and Test-Time Augmentation) individually and their combined effect on the frog vocalization data and the public environmental sounds dataset (ESC-50). The effect of combined data augmentation techniques improved the model's relative accuracy as the size of the dataset decreased. The combination of all four techniques improved the ML model’s classification accuracy on the frog calls dataset by 94%. This study established a data augmentation approach to maximize the classification accuracy with sparse data of frog call recordings, thereby creating a possibility to build a real-world automated field frog species identifier system. Such a system can significantly help in the conservation of frog species in this vital biodiversity hotspot.
Droughts have a wide range of effects, from ecosystems failing and crops dying, to increased illness and decreased water quality. Drought prediction is important because it can help communities, businesses, and governments plan and prepare for these detrimental effects. This study predicts drought conditions by using predictable weather patterns in machine learning models.