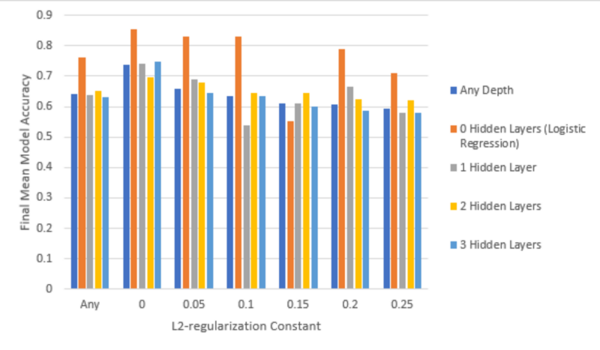
The authors looked at the ability to detect heart disease before the onset of severe clinical symptoms.
Read More...Study of neural network parameters in detecting heart disease
The authors looked at the ability to detect heart disease before the onset of severe clinical symptoms.
Read More...Groundwater prediction using artificial intelligence: Case study for Texas aquifers
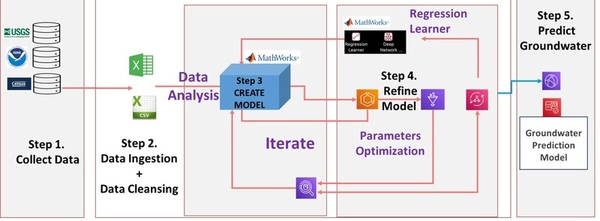
Here, in an effort to develop a model to predict future groundwater levels, the authors tested a tree-based automated artificial intelligence (AI) model against other methods. Through their analysis they found that groundwater levels in Texas aquifers are down significantly, and found that tree-based AI models most accurately predicted future levels.
Read More...Using data science along with machine learning to determine the ARIMA model’s ability to adjust to irregularities in the dataset

Auto-Regressive Integrated Moving Average (ARIMA) models are known for their influence and application on time series data. This statistical analysis model uses time series data to depict future trends or values: a key contributor to crime mapping algorithms. However, the models may not function to their true potential when analyzing data with many different patterns. In order to determine the potential of ARIMA models, our research will test the model on irregularities in the data. Our team hypothesizes that the ARIMA model will be able to adapt to the different irregularities in the data that do not correspond to a certain trend or pattern. Using crime theft data and an ARIMA model, we determined the results of the ARIMA model’s forecast and how the accuracy differed on different days with irregularities in crime.
Read More...Using machine learning to develop a global coral bleaching predictor
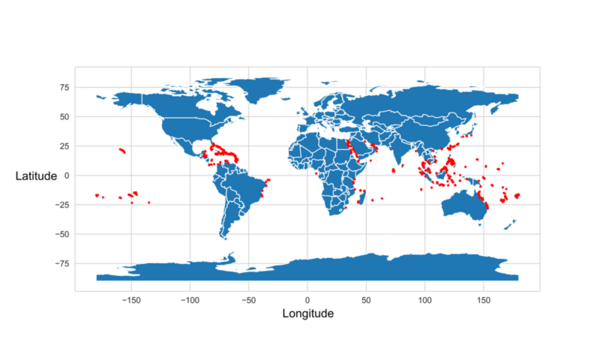
Coral bleaching is a fatal process that reduces coral diversity, leads to habitat loss for marine organisms, and is a symptom of climate change. This process occurs when corals expel their symbiotic dinoflagellates, algae that photosynthesize within coral tissue providing corals with glucose. Restoration efforts have attempted to repair damaged reefs; however, there are over 360,000 square miles of coral reefs worldwide, making it challenging to target conservation efforts. Thus, predicting the likelihood of bleaching in a certain region would make it easier to allocate resources for conservation efforts. We developed a machine learning model to predict global locations at risk for coral bleaching. Data obtained from the Biological and Chemical Oceanography Data Management Office consisted of various coral bleaching events and the parameters under which the bleaching occurred. Sea surface temperature, sea surface temperature anomalies, longitude, latitude, and coral depth below the surface were the features found to be most correlated to coral bleaching. Thirty-nine machine learning models were tested to determine which one most accurately used the parameters of interest to predict the percentage of corals that would be bleached. A random forest regressor model with an R-squared value of 0.25 and a root mean squared error value of 7.91 was determined to be the best model for predicting coral bleaching. In the end, the random model had a 96% accuracy in predicting the percentage of corals that would be bleached. This prediction system can make it easier for researchers and conservationists to identify coral bleaching hotspots and properly allocate resources to prevent or mitigate bleaching events.
Read More...Minimizing distortion with additive manufacturing parts using Machine Learning
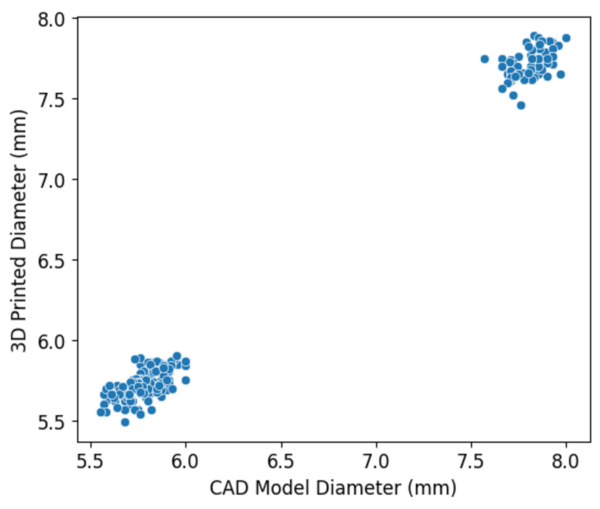
This study explores how to predict and minimize distortion in 3D printed parts, particularly when using affordable PLA filament. The researchers developed a model using a gradient boosting regressor trained on 3D printing data, aiming to predict the necessary CAD dimensions to counteract print distortion.
Read More...Deep sequential models versus statistical models for web traffic forecasting
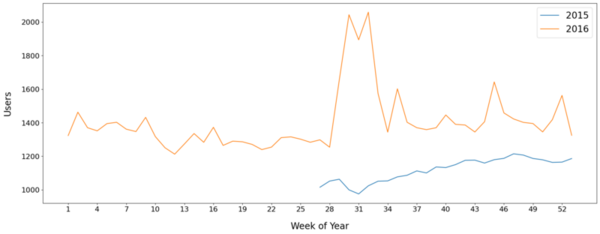
The authors looked at ways to provide better forecasting on website traffic. They found that deep learning models performed better than statistical models.
Read More...Assessing machine learning model efficacy for brain tumor MRI classification: a multi-model approach
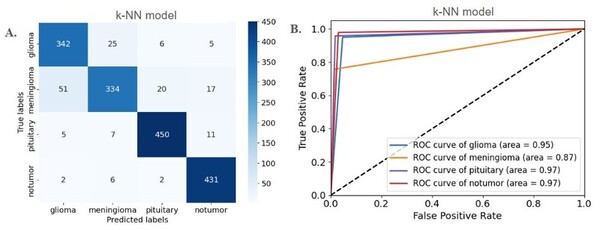
This manuscript explores the performance of five different machine learning models in classifying brain tumors from a dataset of MRI scans. The authors find that several of the models showed >90% accuracy. Thus, the authors suggest that machine learning models demonstrate potential for effective implementation in clinical settings, including as a diagnostic tool that can be used to complement the expertise of neuroradiologists.
Read More...Levering machine learning to distinguish between optimal and suboptimal basketball shooting forms

The authors looked at different ways to build computational resources that would analyze shooting form for basketball players.
Read More...A comparative analysis of machine learning approaches to predict brain tumors using MRI
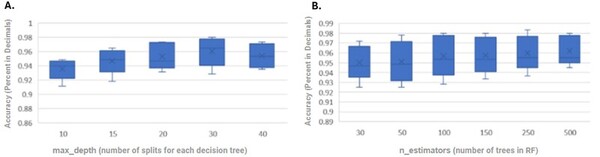
The authors use machine learning on MRI images of brain tissue to predict tumor onset as an avenue for early detection of brain cancer.
Read More...Machine learning predictions of additively manufactured alloy crack susceptibilities
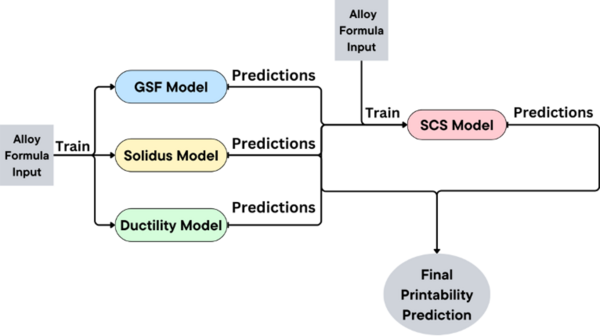
Additive manufacturing (AM) is transforming the production of complex metal parts, but challenges like internal cracking can arise, particularly in critical sectors such as aerospace and automotive. Traditional methods to assess cracking susceptibility are costly and time-consuming, prompting the use of machine learning (ML) for more efficient predictions. This study developed a multi-model ML pipeline that predicts solidification cracking susceptibility (SCS) more accurately by considering secondary alloy properties alongside composition, with Random Forest models showing the best performance, highlighting a promising direction for future research into SCS quantification.
Read More...