Here the authors investigate the use of social media in adults with Autism Spectrum Disorder (ASD) in affecting their ability and opportunities to interact with others. They found that higher usage of Internet correlated with less severe anxiety symptoms and improved social skills.
Read More...Browse Articles
Cleaning up the world’s oceans with underwater laser imaging

Here recognizing the growing amount of plastic waste in the oceans, the authors sought to develop and test laser imaging for the identification of waste in water. They found that while possible, limitations such as increasing depth and water turbidity result in increasing blurriness in laser images. While their image processing methods were somewhat insufficient they identified recent methods to use deep learning-based techniques as a potential avenue to viability for this method.
Read More... The relationship between multilingualism and visual imagery: Investigating aphantasia using the VVIQ
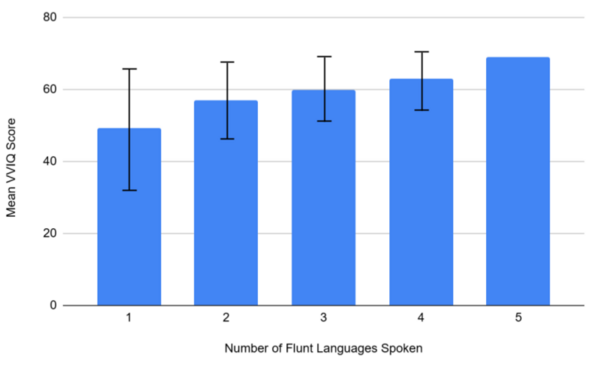
The authors looked at the correlation between being able to speak more than one language (multilingualism) and visual imagery. They found multilingual individuals had higher visual imagery as measured by the VVIQ.
Read More...The impact of conceptual versus memorization-based teaching methods on student performance

The authors looked at how students performed on standardized tests when they were taught material via memorization vs. conceptual based approaches.
Read More...Identifying shark species using an AlexNet CNN model
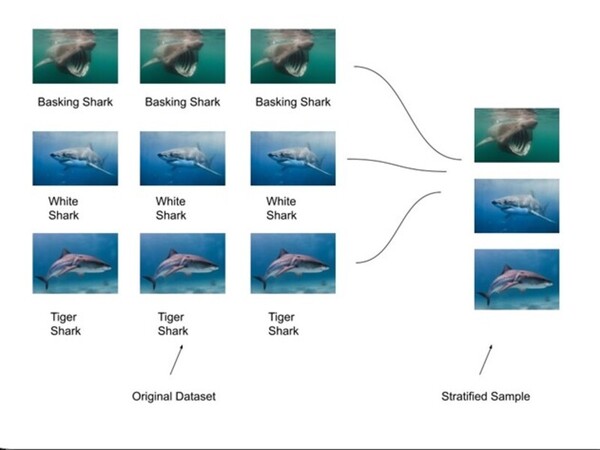
The challenge of accurately identifying shark species is crucial for biodiversity monitoring but is often hindered by time-consuming and labor-intensive manual methods. To address this, SharkNet, a CNN model based on AlexNet, achieved 93% accuracy in classifying shark species using a limited dataset of 1,400 images across 14 species. SharkNet offers a more efficient and reliable solution for marine biologists and conservationists in species identification and environmental monitoring.
Read More...Evaluating TensorFlow image classification in classifying proton collision images for particle colliders
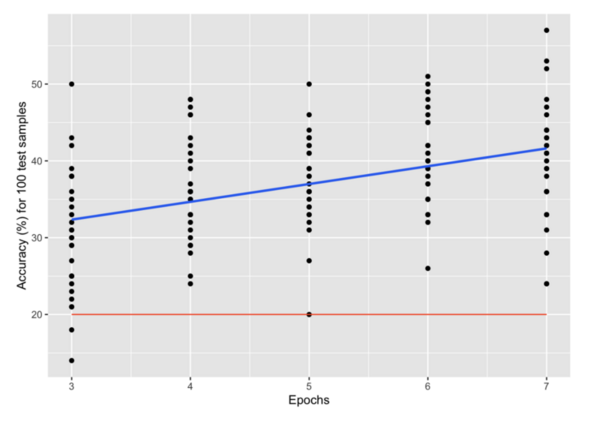
In this study the authors looked at developing a more efficient particle collision classification method with the goal of being able to more efficiently analyze particle trajectories from large-scale particle collisions without loss of accuracy.
Read More...An efficient approach to automated geometry diagram parsing

Here, beginning from an initial interest in the possibility to use a computer to automatically solve a geometry diagram parser, the authors developed their own Fast Geometry Diagram Parser (FastGDP) that uses clustering and corner information. They compared their own methods to a more widely available, method, GeoSolver, finding their own to be an order of magnitude faster in most cases that they considered.
Read More...Deep residual neural networks for increasing the resolution of CCTV images
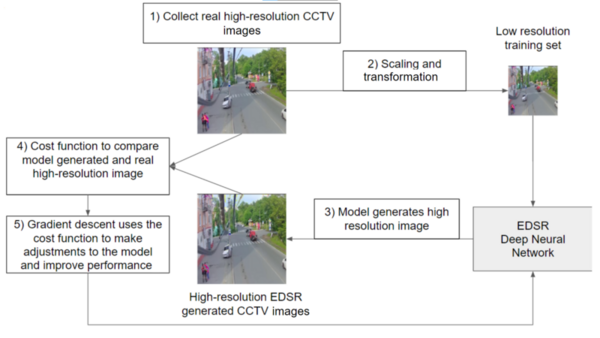
In this study, the authors hypothesized that closed-circuit television images could be stored with improved resolution by using enhanced deep residual (EDSR) networks.
Read More...The Effect of Varying Training on Neural Network Weights and Visualizations
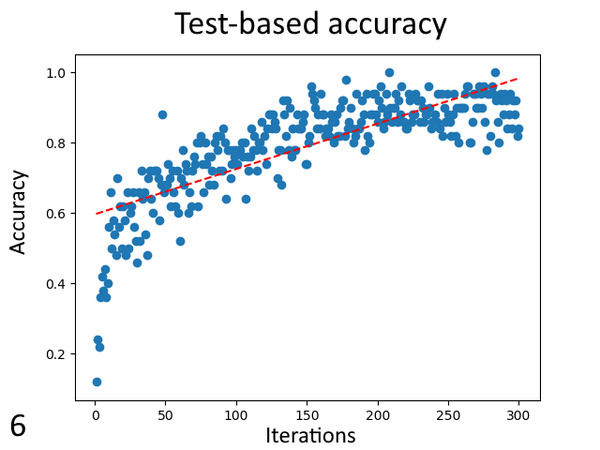
Neural networks are used throughout modern society to solve many problems commonly thought of as impossible for computers. Fountain and Rasmus designed a convolutional neural network and ran it with varying levels of training to see if consistent, accurate, and precise changes or patterns could be observed. They found that training introduced and strengthened patterns in the weights and visualizations, the patterns observed may not be consistent between all neural networks.
Read More...