Machine learning on crowd-sourced data to highlight coral disease
(1) Elwood John Glenn High School, Elwood, NY
https://doi.org/10.59720/20-127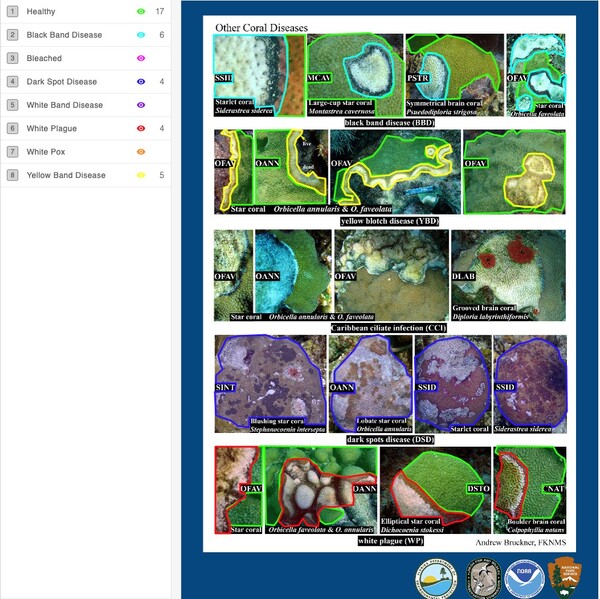
Triggered largely by the warming and pollution of oceans, corals are experiencing bleaching and a variety of diseases caused by the spread of bacteria, fungi, and viruses. Identification of bleached/diseased corals enables implementation of measures to halt or retard disease. Benthic cover analysis, a standard metric used in large databases to assess live coral cover, as a standalone measure of reef health is insufficient for identification of coral bleaching/disease. Proposed herein is a solution that couples machine learning with crowd-sourced data – images from government archives, citizen science projects, and personal images collected by tourists – to build a model capable of identifying healthy, bleached, and/or diseased coral. We collected hundreds of images of corals from open source archives, including the National Oceanic and Atmospheric Administration’s records and the XL Catlin Seaview Survey. The image annotation platform Labelbox was used to highlight regions of interest in each of these images and label them as “healthy”, “bleached”, “black band disease”, “dark spot disease”, “white syndrome”, or “yellow band disease”. These annotations were then used to build, train, and validate a Python-based image classification model, adapted from an open-source Mask R-CNN (region-based convolutional neural network) algorithm. Use of the model on a test set of coral images yields over 85% accuracy in distinguishing healthy versus unhealthy coral. This machine learning-based model has the potential to rapidly analyze a large and growing database of images to identify coral bleaching/disease around the world, thereby enabling effective allocation of resources for preservation of our marine ecosystems.
This article has been tagged with: