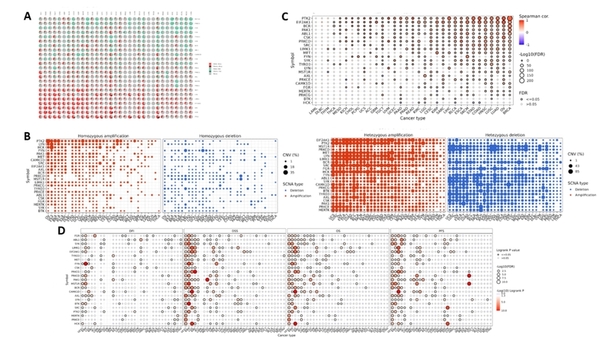
This study analyzes genetic alterations and expression patterns of protein kinases involved in phagocytosis across multiple cancers using TCGA data.
Read More...Protein kinases in phagocytosis (phagocytotic kinome): A promising biomarker set in cancer therapeutics
This study analyzes genetic alterations and expression patterns of protein kinases involved in phagocytosis across multiple cancers using TCGA data.
Read More...Impact of TCERG1 SNP on gene expression and protein interactome in Huntington’s disease

The authors assess a genetic variant within a well-known interaction partner of huntingtin that has been linked to modifying the age of onset of Huntington's disease.
Read More...String analysis of exon 10 of the CFTR gene and the use of Bioinformatics in determination of the most accurate DNA indicator for CF prediction
Cystic fibrosis is a genetic disease caused by mutations in the CFTR gene. In this paper, the authors attempt to identify variations in stretches of up to 8 nucleotides in the protein-coding portions of the CFTR gene that are associated with disease development. This would allow screening of newborns or even fetuses in utero to determine the likelihood they develop cystic fibrosis.
Read More...Can Children Acquire Their Parents’ History of Fracture?
While the genetic basis of hip fracture risk has been studied extensively in adults, it is not known whether parental history of bone fractures affects their children's fracture risk. In this article, the authors investigated whether a parental history of bone fractures influences the rate of fractures in their children. They found that adolescent children whose parents had a more extensive history of fractures were more likely to have a history of fractures themselves, suggesting that parents' medical histories may be an important consideration in future pediatric health research.
Read More...Aberrant response to dexamethasone suppression test associated with inflammatory response in MDD patients
Major depressive disorder (MDD) is a prevalent mood disorder. The direct causes and biological mechanisms of depression still elude understanding, though genetic factors have been implicated. This study looked to identify the mechanism behind the aberrant response to the dexamethasone suppression test (DST) displayed by MDD patients, in which they display a lack of cortisol suppression. Analysis revealed several pro-inflammatory genes that were significant and differentially expressed between affected and non-affected groups in response to the DST. Looking at ways to decrease the inflammatory response could have implications for treatment and may explain why some people treated for depression still display symptoms or may lead researchers to different classes of drugs for treatment.
Read More...The effect of Omega-3 on bovine blood cells as a potential remedy for Cerebral Cavernous Malformations

Here, the authors investigated if dietary Omega-3 fatty acids could reduce the potential for cerebral cavernous malformations, which are brain lesions that occur due to a genetic mutation where high membrane permeability occurs between endothelial cell junctions. In a bovine-based study where some cows were fed an Omega-3 diet, the authors found the membranes of bovine blood cells increased in thickness with Omega-3 supplementation. As a result, they suggest that dietary Omega-3 could be considered as a possible preventative measure for cerebral cavernous malformations.
Read More...siRNA-dependent KCNMB2 silencing inhibits lung cancer cell proliferation and promotes cell death
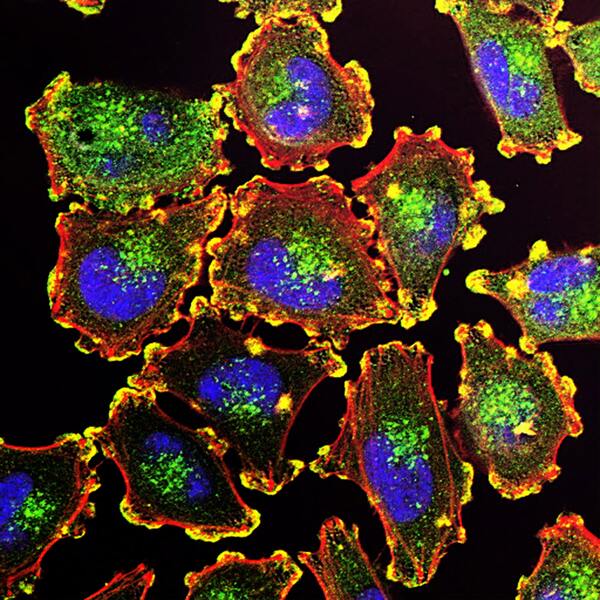
Here, seeking to better understand the genetic associations underlying non-small cell lung cancer, the authors screened hundreds of genes, identifying that KCNMB2 upregulation was significantly correlated with poor prognoses in lung cancer patients. Based on this, they used small interfering RNA to decrease the expression of KCNMB2 in A549 lung cancer cells, finding decreased cell proliferation and increased lung cancer cell death. They suggest this could lead to a new potential target for lung cancer therapies.
Read More...Characterization and Phylogenetic Analysis of the Cytochrome B Gene (cytb) in Salvelinus fontinalis, Salmo trutta and Salvelinus fontinalis X Salmo trutta Within the Lake Champlain Basin

Recent declines in the brook trout population of the Lake Champlain Basin have made the genetic screening of this and other trout species of utmost importance. In this study, the authors collected and analyzed 21 DNA samples from Lake Champlain Basin trout populations and performed a phylogenetic analysis on these samples using the cytochrome b gene. The findings presented in this study may influence future habitat decisions in this region.
Read More...Innovative Treatment for Reducing Senescence and Revitalizing Aging Cells through Gene Silencing
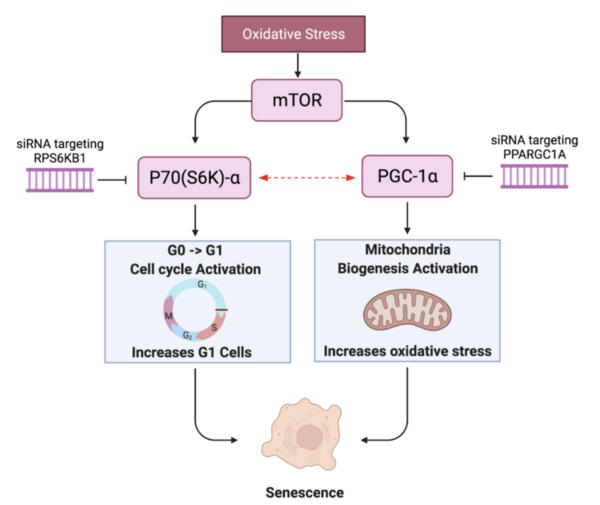
Cellular senescence plays a key role in aging cells and is attributed to a number of disease and pathology. These authors find that genetic editing of both RPS6KB1 and PPARGC1A revitalizes a human skin fibroblast cell line.
Read More...The Impacts of Varying Types of Light on the Growth of Five Arabidopsis Varieties

Arabadopsis, “the fruit fly of plants”, is an easy to grow plant system for genetic manipulation. Here, researchers tested the effects of varied light conditions on plants with specific mutations in the light sensing pathways.
Read More...