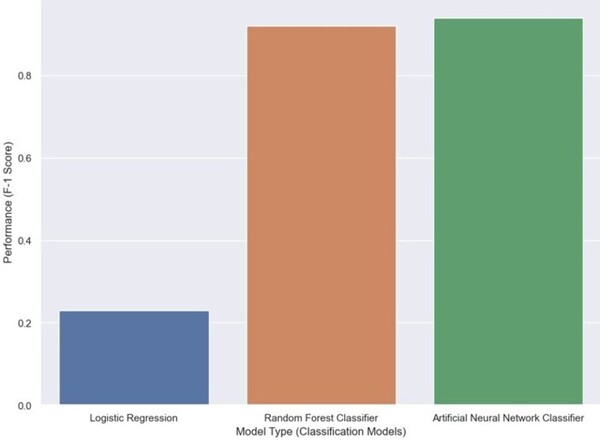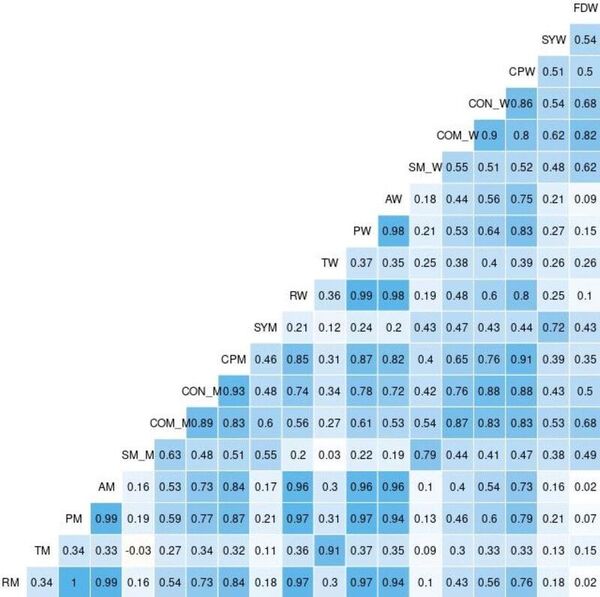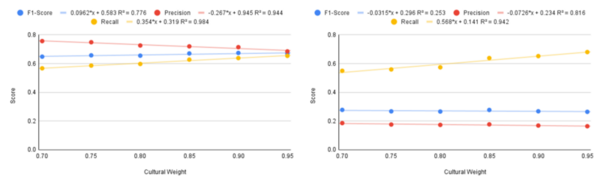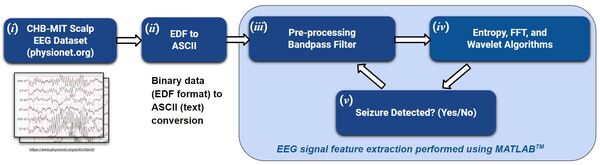
Each year, over 100,000 patients die from Sudden Unexpected Death in Epilepsy (SUDEP). A reliable seizure warning system can help patients stay safe. This work presents a comprehensive, comparative analysis of three different signal processing algorithms for automated seizure/ictal detection. The experimental results show that the proposed methods can be effective for accurate automated seizure detection and monitoring in clinical care.
Read More...