In this study the authors looked at developing a more efficient particle collision classification method with the goal of being able to more efficiently analyze particle trajectories from large-scale particle collisions without loss of accuracy.
Every year, around 40% of undergraduate students in the United States discontinue their studies, resulting in a loss of valuable education for students and a loss of money for colleges. Even so, colleges across the nation struggle to discover the underlying causes of these high dropout rates. In this paper, the authors discuss the use of machine learning to find correlations between the built environment factors and the retention rates of colleges. They hypothesized that one way for colleges to improve their retention rates could be to improve the physical characteristics of their campus to be more pleasing. The authors used image classification techniques to look at images of colleges and correlate certain features like colors, cars, and people to higher or lower retention rates. With three possible options of high, medium, and low retention rates, the probability that their models reached the right conclusion if they simply chose randomly was 33%. After finding that this 33%, or 0.33 mark, always fell outside of the 99% confidence intervals built around their models’ accuracies, the authors concluded that their machine learning techniques can be used to find correlations between certain environmental factors and retention rates.
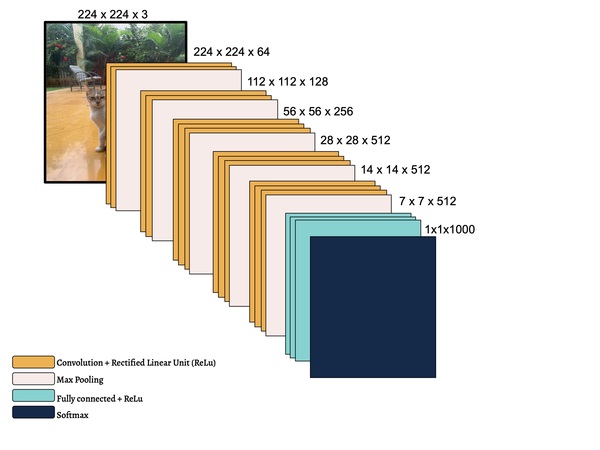
With the advance of technology, artificial intelligence (AI) is now applied widely in society. In the study of AI, machine learning (ML) is a subfield in which a machine learns to be better at performing certain tasks through experience. This work focuses on the convolutional neural network (CNN), a framework of ML, applied to an image classification task. Specifically, we analyzed the performance of the CNN as the type of neural activation function changes.
In this study, the authors seek to improve a machine learning algorithm used for image classification: identifying male and female images. In addition to fine-tuning the classification model, they investigate how accuracy is affected by their changes (an important task when developing and updating algorithms). To determine accuracy, a set of images is used to train the model and then a separate set of images is used for validation. They found that the validation accuracy was close to the training accuracy. This study contributes to the expanding areas of machine learning and its applications to image identification.
Using facial recognition as a use-case scenario, we attempt to identify sources of bias in a model developed using transfer learning. To achieve this task, we developed a model based on a pre-trained facial recognition model, and scrutinized the accuracy of the model’s image classification against factors such as age, gender, and race to observe whether or not the model performed better on some demographic groups than others. By identifying the bias and finding potential sources of bias, his work contributes a unique technical perspective from the view of a small scale developer to emerging discussions of accountability and transparency in AI.
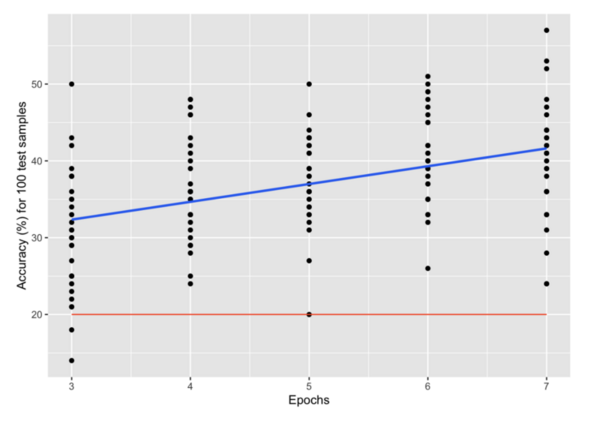
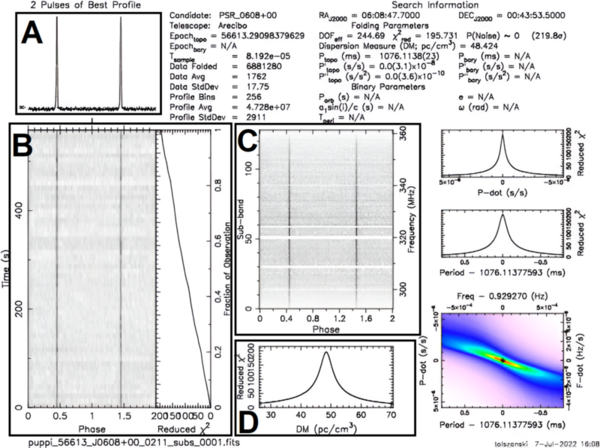
This study investigates how the hyperparameters epochs and batch size affect the classification accuracy of a convolutional neural network (CNN) trained on pulsar candidate data. Our results reveal that accuracy improves with increasing number of epochs and smaller batch sizes, suggesting that with optimized hyperparameters, high accuracy may be achievable with minimal training. These findings offer insights that could help create more efficient machine learning classification models for pulsar signal detection, with the potential of accelerating pulsar discovery and advancing astrophysical research.
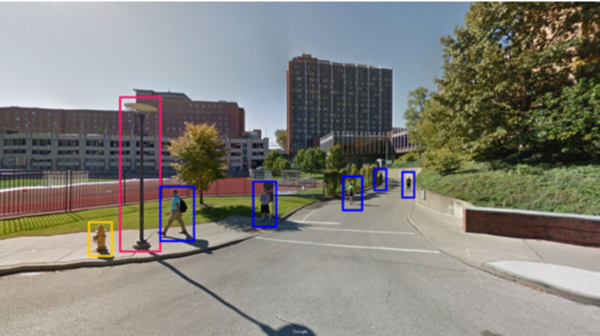
Intelligent vehicles utilize a combination of video-enabled object detection and radar data to traverse safely through surrounding environments. However, since the most momentary missteps in these systems can cause devastating collisions, the margin of error in the software for these systems is small. In this paper, we hypothesized that a novel object detection system that improves detection accuracy and speed of detection during adverse weather conditions would outperform industry alternatives in an average comparison.
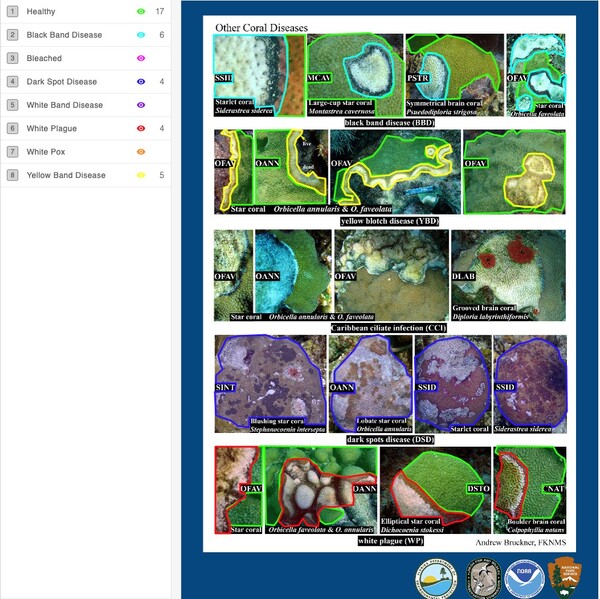
Triggered largely by the warming and pollution of oceans, corals are experiencing bleaching and a variety of diseases caused by the spread of bacteria, fungi, and viruses. Identification of bleached/diseased corals enables implementation of measures to halt or retard disease. Benthic cover analysis, a standard metric used in large databases to assess live coral cover, as a standalone measure of reef health is insufficient for identification of coral bleaching/disease. Proposed herein is a solution that couples machine learning with crowd-sourced data – images from government archives, citizen science projects, and personal images collected by tourists – to build a model capable of identifying healthy, bleached, and/or diseased coral.
Here, the authors used machine learning to analyze microscopic images of hair, quantifying various features to distinguish individuals, even within families where traditional DNA analysis is limited. The Discriminant Analysis (DA) model achieved the highest accuracy (88.89%) in identifying individuals, demonstrating its potential to improve the reliability of hair evidence in forensic investigations.