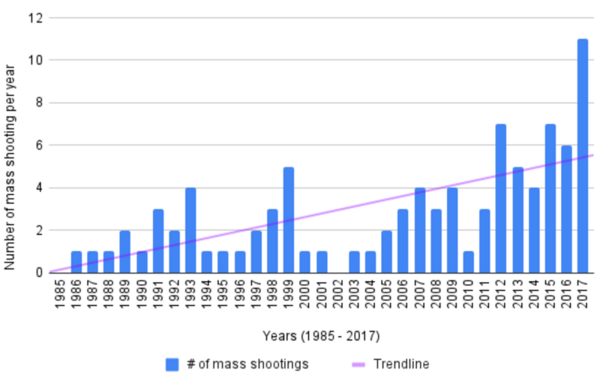
Researching gun violence and mass shootings in the U.S. is difficult due to the lack of consistent data collection. Some studies have linked mass shootings to personal financial stress, but little formal research exists on the impact of broader economic conditions. This study hypothesized an inverse relationship between mass shootings and economic performance, using the S&P 500 and unemployment rate as indicators.
Read More...