The authors looked at developing a PMMA nanoparticle fabric dye that would be more sustainable compared to traditional fabric dyes. They were able to create PMMA based dyes in different colors that were also durable (i.e., did not fade quickly on fabric).
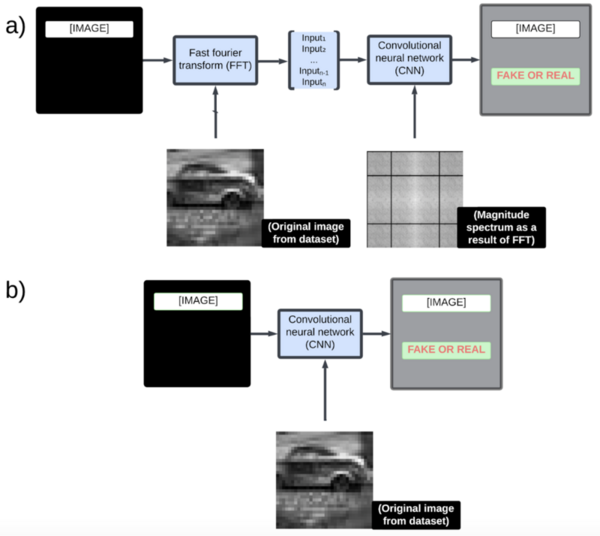
Recent advances in generative AI have made it increasingly hard to distinguish real images from AI-generated ones. Traditional detection models using CNNs or U-net architectures lack precision because they overlook key spatial and frequency domain details. This study introduced a hybrid model combining Convolutional Neural Networks (CNN) with Fast Fourier Transform (FFT) to better capture subtle edge and texture patterns.
Here, the authors used machine learning to analyze microscopic images of hair, quantifying various features to distinguish individuals, even within families where traditional DNA analysis is limited. The Discriminant Analysis (DA) model achieved the highest accuracy (88.89%) in identifying individuals, demonstrating its potential to improve the reliability of hair evidence in forensic investigations.
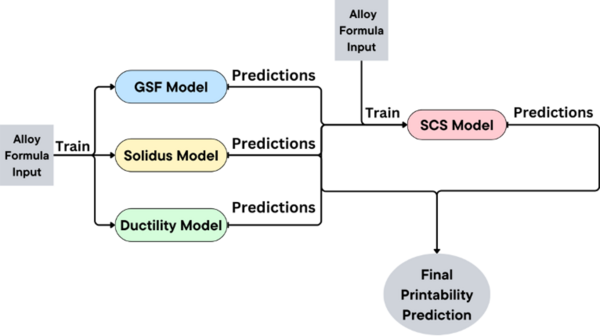
Additive manufacturing (AM) is transforming the production of complex metal parts, but challenges like internal cracking can arise, particularly in critical sectors such as aerospace and automotive. Traditional methods to assess cracking susceptibility are costly and time-consuming, prompting the use of machine learning (ML) for more efficient predictions. This study developed a multi-model ML pipeline that predicts solidification cracking susceptibility (SCS) more accurately by considering secondary alloy properties alongside composition, with Random Forest models showing the best performance, highlighting a promising direction for future research into SCS quantification.
Coronary heart disease (CHD) is the leading cause of death in the U.S., responsible for nearly 700,000 deaths in 2021, and is marked by artery clogging that can lead to heart attacks. Traditional prediction methods require expensive clinical tests, but a new study explores using machine learning on demographic, clinical, and behavioral survey data to predict CHD.
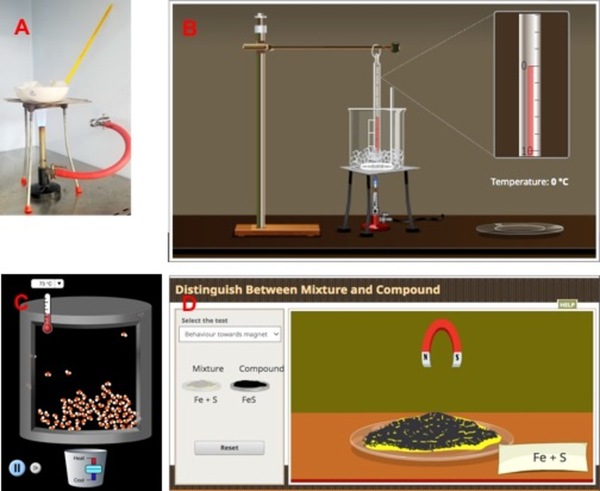
Virtual labs have been gaining popularity over the last few years, especially during the worldwide lockdown due to the COVID-19 pandemic. In this study, the suitability of virtual labs for school chemistry experiments is addressed and their effectiveness is compared to traditional physical lab experiments by focusing on physical and human resources, convenience, cost, safety, and time involved as well as topic "matter".
Acquired drug resistance is an increasing challenge in treating cancer with chemotherapy. One mechanism
behind this resistance is the increased inflammation that supports the progression and development of
cancer that arises because of the drug’s presence. Integrative oncology is the field that focuses on including natural products alongside traditional therapy to create a treatment that focuses on holistic patient well-being.
In this study, the authors demonstrate that the use of an herbal formulation, consisting of turmeric and green tea, alongside a traditional chemotherapeutic drug, 5-fluorouracil (FU) significantly decreases the level of cytokines produced in breast cancer cells when compared to the levels produced when exposed solely to the chemo drug. The authors conclude that this combination of treatment, based on the principle of integrative oncology, shows potential for reducing the resistance against treatment conferred through increased inflammation. Consequently, this suggests a prospective way forward in improving the efficacy of cancer treatment.
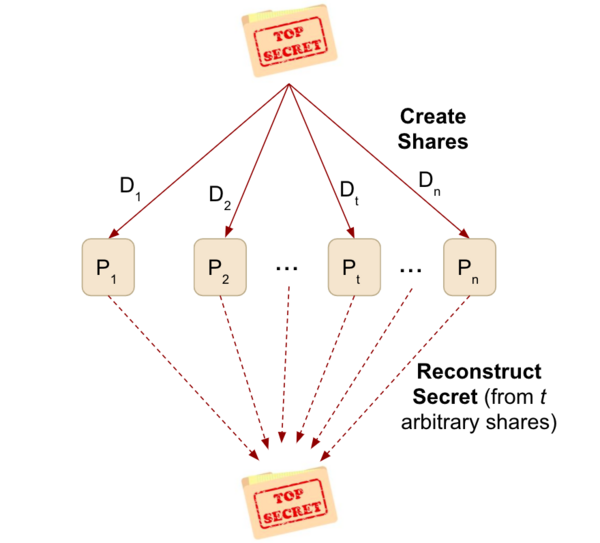
In this study, the authors develop an architecture to implement in a cloud-based database used by law firms to ensure confidentiality, availability, and integrity of attorney documents while maintaining greater efficiency than traditional encryption algorithms. They assessed whether the architecture satisfies necessary criteria and tested the overall file sizes the architecture could process. The authors found that their system was able to handle larger file sizes and fit engineering criteria. This study presents a valuable new tool that can be used to ensure law firms have adequate security as they shift to using cloud-based storage systems for their files.
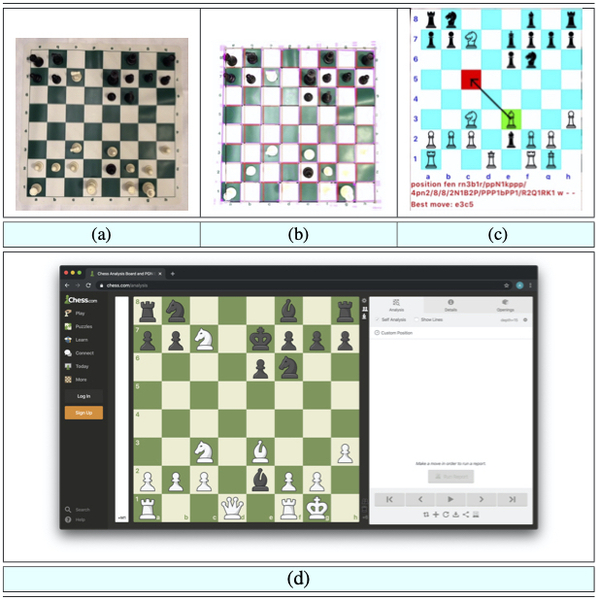
In this study the authors develop an app for faster chess game entry method to help chess learners improve their game. This culminated in the Augmented Reality Chess Analyzer (ARChessAnalyzer) which uses traditional image and vision techniques for chess board recognition and Convolutional Neural Networks (CNN) for chess piece recognition.
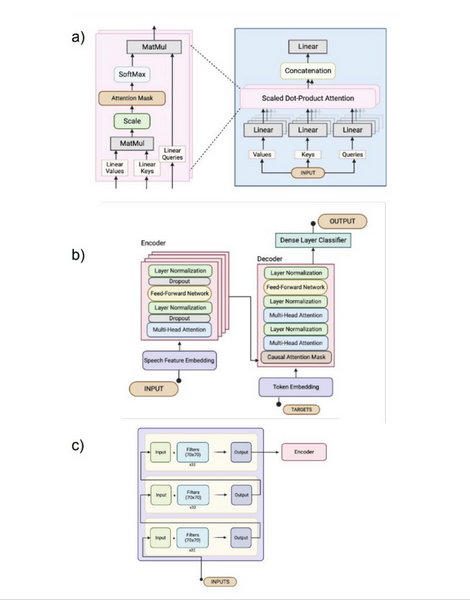
Brain-Computer Interface (BCI) allows users, especially those with paralysis, to control devices through brain activity. This study explored using a custom transformer model to decode neural signals into handwritten text for individuals with limited motor skills, comparing its performance to a traditional RNN-based BCI.