In this study the authors looked at the ability of artificial intelligence to detect tempo, rhythm, and intonation of a piece played on violin. Technology such as this would allow for students to practice and get feedback without the need of a teacher.
Autonomous drone imaging combined with machine learning offers a promising approach for early detection of invasive species. In this study, students built an autonomous drone and compared three models: CNN, SGDC, and XGBoost, to identify Brassica nigra from aerial footage. Their results show that CNNs most effectively recognize key visual features, demonstrating strong potential for supporting conservation and invasive plant management.
Here in an effort to better understand how our brains process and remember different categories of information, the authors assessed working memory capacity using an operation span task. They found that individuals with higher working memory capacity had higher overall higher task accuracy regardless of the type of category or the type of visual distractors they had to process. They suggest this may play a role in how some students may be less affected by distracting stimuli compared to others.
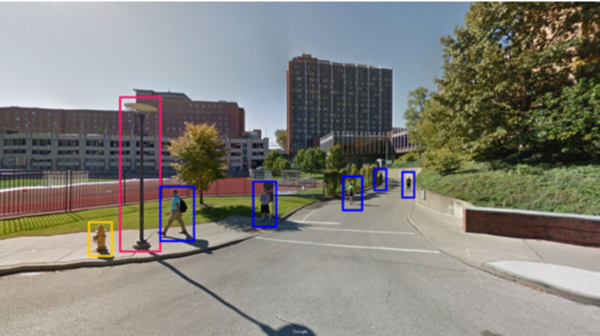
Every year, around 40% of undergraduate students in the United States discontinue their studies, resulting in a loss of valuable education for students and a loss of money for colleges. Even so, colleges across the nation struggle to discover the underlying causes of these high dropout rates. In this paper, the authors discuss the use of machine learning to find correlations between the built environment factors and the retention rates of colleges. They hypothesized that one way for colleges to improve their retention rates could be to improve the physical characteristics of their campus to be more pleasing. The authors used image classification techniques to look at images of colleges and correlate certain features like colors, cars, and people to higher or lower retention rates. With three possible options of high, medium, and low retention rates, the probability that their models reached the right conclusion if they simply chose randomly was 33%. After finding that this 33%, or 0.33 mark, always fell outside of the 99% confidence intervals built around their models’ accuracies, the authors concluded that their machine learning techniques can be used to find correlations between certain environmental factors and retention rates.
In this study, the authors investigate the effect of remote learning (due to the COVID-19 pandemic) on sleeping habits amongst teenagers in Ohio. Using survey results, sleep habits and attitudes toward school were assessed before and after the COVID-19 pandemic.
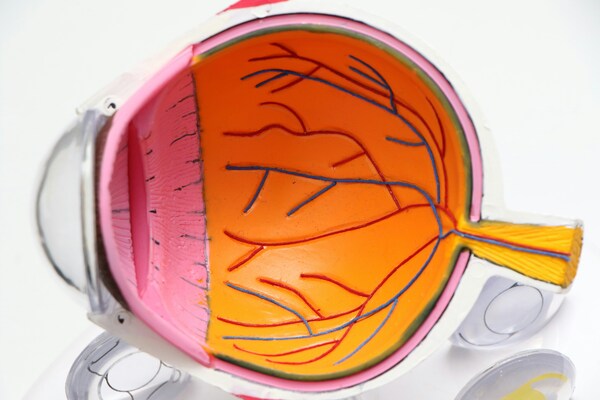
This study examined whether eye color affects photophobia and vision in elementary school students and staff, finding no significant relationship between eye color, light sensitivity, or visual acuity. However, photophobia was common across age groups, highlighting the need for greater awareness of light sensitivity in learning environments.
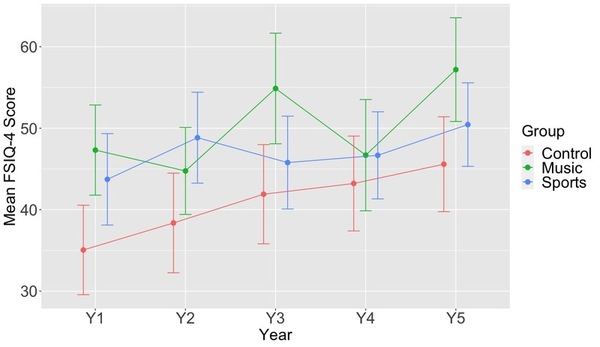
The study explores how music and sports impact cognitive development in young children, particularly in relation to learning disorders like ADHD and dyslexia.
Here, the authors investigated the effects of an interventional psychology on the study habits of high school students specifically related to the use of electronic distractions such as social media or texting, listening to music, or watching TV. They reported varying degrees of success between the control and intervention groups, suggesting that the methods of habit-breaking for students merits further study.
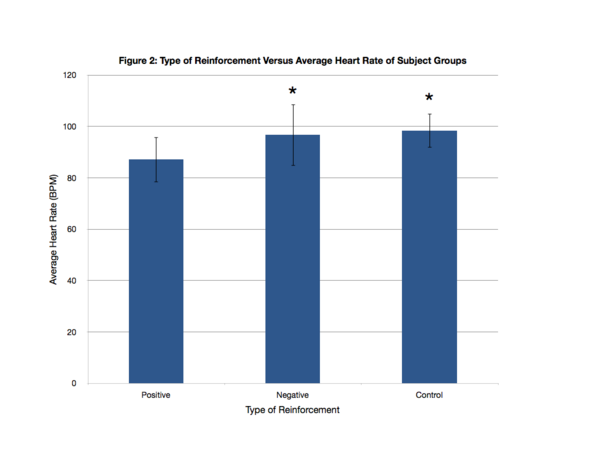
What type of motivation is more effective: reward or punishment? In this study, the authors assess the effects of positive or negative on the math scores of sixth graders.