With advancements in machine learning a large data scale, high throughput virtual screening has become a more attractive method for screening drug candidates. This study compared the accuracy of molecular descriptors from two cheminformatics Mordred and PaDEL, software libraries, in characterizing the chemo-structural composition of 53 compounds from the non-nucleoside reverse transcriptase inhibitors (NNRTI) class. The classification model built with the filtered set of descriptors from Mordred was superior to the model using PaDEL descriptors. This approach can accelerate the identification of hit compounds and improve the efficiency of the drug discovery pipeline.
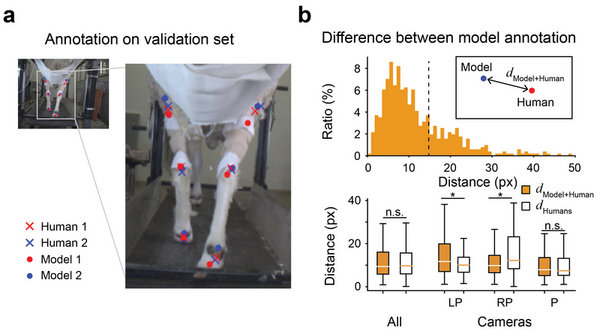
The application of machine learning techniques has facilitated the automatic annotation of behavior in video sequences, offering a promising approach for ethological studies by reducing the manual effort required for annotating each video frame. Nevertheless, before solely relying on machine-generated annotations, it is essential to evaluate the accuracy of these annotations to ensure their reliability and applicability. While it is conventionally accepted that there cannot be a perfect annotation, the degree of error associated with machine-generated annotations should be commensurate with the error between different human annotators. We hypothesized that machine learning supervised with adequate human annotations would be able to accurately predict body parts from video sequences. Here, we conducted a comparative analysis of the quality of annotations generated by humans and machines for the body parts of sheep during treadmill walking. For human annotation, two annotators manually labeled six body parts of sheep in 300 frames. To generate machine annotations, we employed the state-of-the-art pose-estimating library, DeepLabCut, which was trained using the frames annotated by human annotators. As expected, the human annotations demonstrated high consistency between annotators. Notably, the machine learning algorithm also generated accurate predictions, with errors comparable to those between humans. We also observed that abnormal annotations with a high error could be revised by introducing Kalman Filtering, which interpolates the trajectory of body parts over the time series, enhancing robustness. Our results suggest that conventional transfer learning methods can generate behavior annotations as accurate as those made by humans, presenting great potential for further research.
In the United States, there are currently 17.8 million affected by atopic dermatitis (AD), commonly known as eczema. It is characterized by itching and skin inflammation. AD patients are at higher risk for infections, depression, cancer, and suicide. Genetics, environment, and stress are some of the causes of the disease. With the rise of personalized medicine and the acceptance of gene-editing technologies, AD-related variations need to be identified for treatment. Genome-wide association studies (GWAS) have associated the Filaggrin (FLG) gene with AD but have not identified specific problematic single nucleotide polymorphisms (SNPs). This research aimed to refine known SNPs of FLG for gene editing technologies to establish a causal link between specific SNPs and the diseases and to target the polymorphisms. The research utilized R and its Bioconductor packages to refine data from the National Center for Biotechnology Information's (NCBI's) Variation Viewer. The algorithm filtered the dataset by coding regions and conserved domains. The algorithm also removed synonymous variations and treated non-synonymous, frameshift, and nonsense separately. The non-synonymous variations were refined and ordered by the BLOSUM62 substitution matrix. Overall, the analysis removed 96.65% of data, which was redundant or not the focus of the research and ordered the remaining relevant data by impact. The code for the project can also be repurposed as a tool for other diseases. The research can help solve GWAS's imprecise identification challenge. This research is the first step in providing the refined databases required for gene-editing treatment.
In this study, the biodiversity of marine animals was studied at different locations along a mangrove, which is a salt-tolerant shrub with elaborate root structures that is found on tropical coastlines.
This manuscript evaluates peak detection algorithms for feature extraction in EMG-based hand gesture recognition using a random forest classifier. The study demonstrates that wavelet-based peak detection features achieve the highest classification accuracy (96.5%), outperforming other methods. The results highlight the potential of peak features to improve EMG-based prosthetic control systems.
Here the authors introduce pressing filtration as a novel, efficient, and low-energy method for extracting dietary fiber from cabbage, which successfully retains heat-sensitive nutrients and achieves a high fiber yield. The study demonstrates the scalability and economic viability of this technique for commercial use, highlighting that the resulting high-fiber cabbage powder can be incorporated into familiar foods like hamburger buns and beef patties without compromising taste or sensory quality.
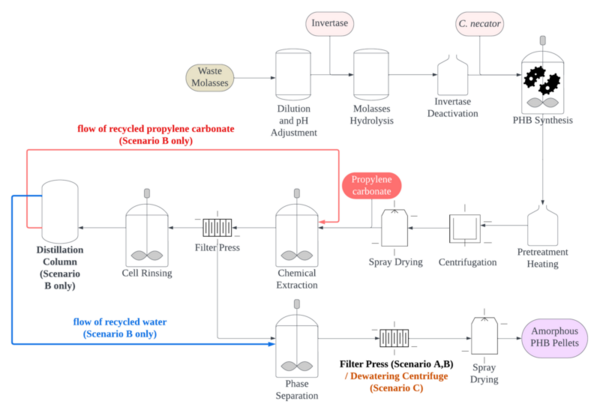
The authors looked at alternative production processes for PHB plastic in an effort to reduce environmental impact. They found that no alternative process was able to significantly decrease the environmental impact of PHB production, but that optimizing dewatering steps during production could lead to the largest improvement on environmental impact.
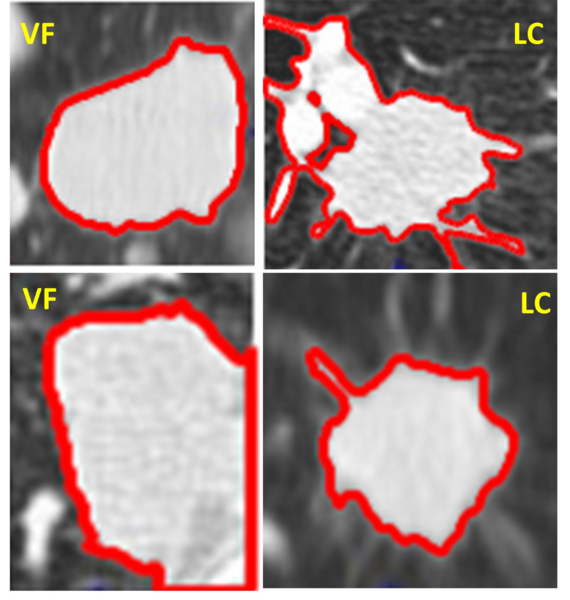
Pulmonary diseases like lung cancer and valley fever pose serious health challenges, making accurate and rapid diagnostics essential. This study developed a MATLAB-based software tool that uses computer vision techniques to differentiate between these diseases by analyzing features of lung nodules in CT scans, achieving higher precision than traditional methods.
One-third of the world's people do not have access to clean drinking water. Nadella and Nadella tackle this issue by testing a low-cost filtration system for removing heavy metal and bacteria from water.

.png)