Here, recognizing the recognizing the growing threat of non-biodegradable plastic waste, the authors investigated the ability to use a modified enzyme identified in bacteria to decompose polyethylene terephthalate (PET). They used simulations to screen and identify an optimized enzyme based on machine learning models. Ultimately, they identified a potential mutant PETases capable of decomposing PET with improved thermal stability.
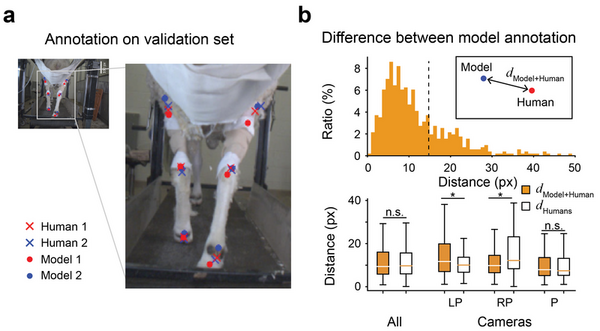
The application of machine learning techniques has facilitated the automatic annotation of behavior in video sequences, offering a promising approach for ethological studies by reducing the manual effort required for annotating each video frame. Nevertheless, before solely relying on machine-generated annotations, it is essential to evaluate the accuracy of these annotations to ensure their reliability and applicability. While it is conventionally accepted that there cannot be a perfect annotation, the degree of error associated with machine-generated annotations should be commensurate with the error between different human annotators. We hypothesized that machine learning supervised with adequate human annotations would be able to accurately predict body parts from video sequences. Here, we conducted a comparative analysis of the quality of annotations generated by humans and machines for the body parts of sheep during treadmill walking. For human annotation, two annotators manually labeled six body parts of sheep in 300 frames. To generate machine annotations, we employed the state-of-the-art pose-estimating library, DeepLabCut, which was trained using the frames annotated by human annotators. As expected, the human annotations demonstrated high consistency between annotators. Notably, the machine learning algorithm also generated accurate predictions, with errors comparable to those between humans. We also observed that abnormal annotations with a high error could be revised by introducing Kalman Filtering, which interpolates the trajectory of body parts over the time series, enhancing robustness. Our results suggest that conventional transfer learning methods can generate behavior annotations as accurate as those made by humans, presenting great potential for further research.
In the United States, there are currently 17.8 million affected by atopic dermatitis (AD), commonly known as eczema. It is characterized by itching and skin inflammation. AD patients are at higher risk for infections, depression, cancer, and suicide. Genetics, environment, and stress are some of the causes of the disease. With the rise of personalized medicine and the acceptance of gene-editing technologies, AD-related variations need to be identified for treatment. Genome-wide association studies (GWAS) have associated the Filaggrin (FLG) gene with AD but have not identified specific problematic single nucleotide polymorphisms (SNPs). This research aimed to refine known SNPs of FLG for gene editing technologies to establish a causal link between specific SNPs and the diseases and to target the polymorphisms. The research utilized R and its Bioconductor packages to refine data from the National Center for Biotechnology Information's (NCBI's) Variation Viewer. The algorithm filtered the dataset by coding regions and conserved domains. The algorithm also removed synonymous variations and treated non-synonymous, frameshift, and nonsense separately. The non-synonymous variations were refined and ordered by the BLOSUM62 substitution matrix. Overall, the analysis removed 96.65% of data, which was redundant or not the focus of the research and ordered the remaining relevant data by impact. The code for the project can also be repurposed as a tool for other diseases. The research can help solve GWAS's imprecise identification challenge. This research is the first step in providing the refined databases required for gene-editing treatment.
In this article, the authors identify the characteristics that make a book a best-seller. Knowing what, besides content, predicts the success of a book can help publishers maximize the success of their print products.
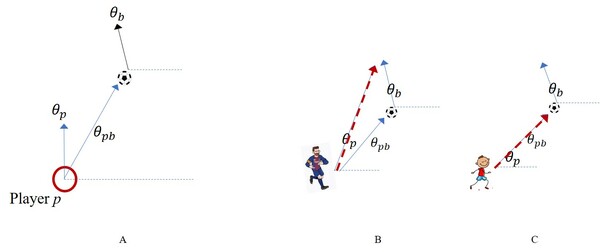
In this article, the authors use datasets of professional and youth soccer players' movements to map and statistically compare them. Analysis compared movements that led to goals or no-goals and differences between pros and youth.
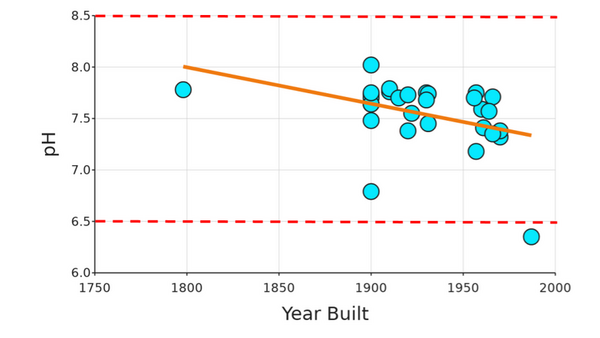
The authors looked at differences in water quality between Chinatown and Bayside. They wanted to look at the racial and economic demographics of each region and how that correlated to access to clean drinking water. Ultimately they did not find any significant differences in water quality, but identified important future directions for this work.
Cosmic rays are high-energy astronomical particles originating from various sources across the universe. Here, The authors sought to understand how surface-level cosmic-ray muon flux is affected by atmospheric attenuation by measuring the variation in relative muon-flux rate relative to zenith angle, testing the hypothesis that muons follow an exponential attenuation model. The attenuation model predicts an attenuation length of 6.3 km. This result implies that only a maximum of 24% of muons can reach the Earth’s surface, due to both decay and atmospheric interactions.
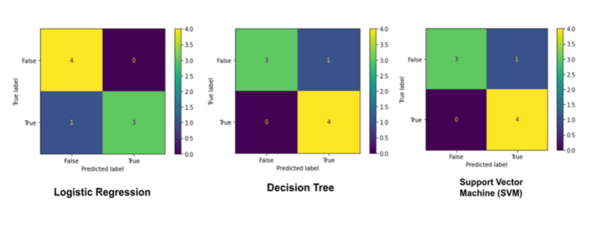
The authors trained a machine learning model to detect kidney stones based on characteristics of urine. This method would allow for detection of kidney stones prior to the onset of noticeable symptoms by the patient.
With advancements in machine learning a large data scale, high throughput virtual screening has become a more attractive method for screening drug candidates. This study compared the accuracy of molecular descriptors from two cheminformatics Mordred and PaDEL, software libraries, in characterizing the chemo-structural composition of 53 compounds from the non-nucleoside reverse transcriptase inhibitors (NNRTI) class. The classification model built with the filtered set of descriptors from Mordred was superior to the model using PaDEL descriptors. This approach can accelerate the identification of hit compounds and improve the efficiency of the drug discovery pipeline.
In this work, the authors sought to provide an original experiment to investigate the conflict over whether males or females tend to exhibit greater accuracy or confidence in their memories. By using an online portal to obtain a convenience sample, the authors found that their results suggest that though males tend to be more confident regarding their memories, they may in fact remember fewer details. The authors suggest that these findings merit further research before making systematic changes regarding crime scene recall settings.