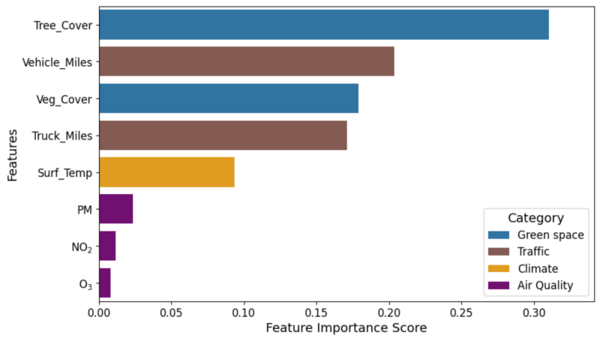
This study explored how green spaces, climate, traffic, and air quality (GCTA) collectively influence asthma-related emergency department visits in the U.S using machine learning models and explainable AI.
Read More...Environmental contributors of asthma via explainable AI: Green spaces, climate, traffic & air quality
This study explored how green spaces, climate, traffic, and air quality (GCTA) collectively influence asthma-related emergency department visits in the U.S using machine learning models and explainable AI.
Read More...Lung cancer AI-based diagnosis through multi-modal integration of clinical and imaging data
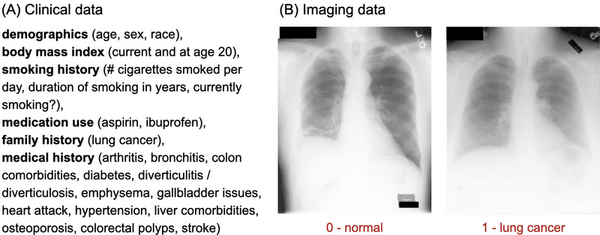
Lung cancer is highly fatal, largely due to late diagnoses, but early detection can greatly improve survival. This study developed three models to enhance early diagnosis: an MLP for clinical data, a CNN for imaging data, and a hybrid model combining both.
Read More...Impact of Silverado Fire on soil carbon
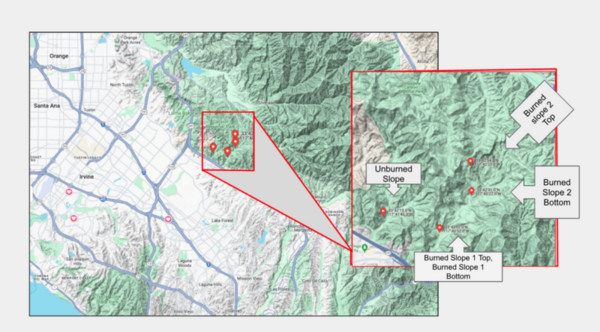
Soil stores three times more carbon than the atmosphere, making small changes in its storage and release crucial for carbon cycling and climate models. This study examined the impact of the 2020 California Silverado Fire on pyrogenic carbon (PyC) deposits using nitrogen and carbon isotopes as proxies. While the results showed significant variability in δ¹⁵N, δ¹³C, total carbon, and total nitrogen across sites, they did not support the hypothesis that wildfire increases δ¹⁵N while keeping δ¹³C constant, emphasizing the need for location-based controls when using δ¹⁵N to track PyC.
Read More...The utilization of Artificial Intelligence in enabling the early detection of brain tumors
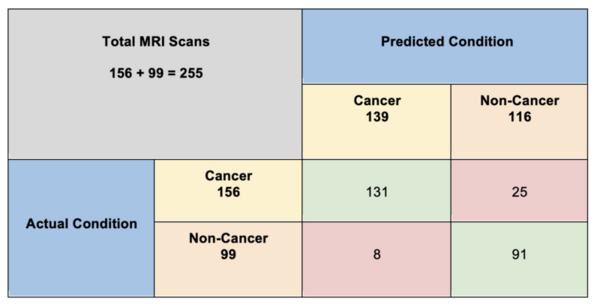
AI analysis of brain scans offers promise for helping doctors diagnose brain tumors. Haider and Drosis explore this field by developing machine learning models that classify brain scans as "cancer" or "non-cancer" diagnoses.
Read More...Survival analysis in cardiovascular epidemiology: nexus between heart disease and mortality
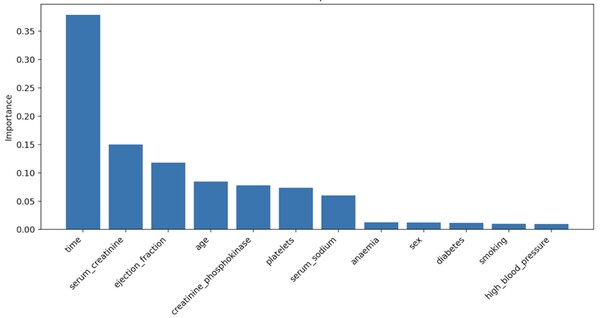
In 2021, over 20 million people died from cardiovascular diseases, highlighting the need for a deeper understanding of factors influencing heart failure outcomes. This study examined multiple variables affecting mortality after heart failure, using random forest models to identify time, serum creatinine, and ejection fraction as key predictors. These findings could contribute to personalized medicine, improving survival rates by tailoring treatment strategies for heart failure patients.
Read More...Gradient boosting with temporal feature extraction for modeling keystroke log data
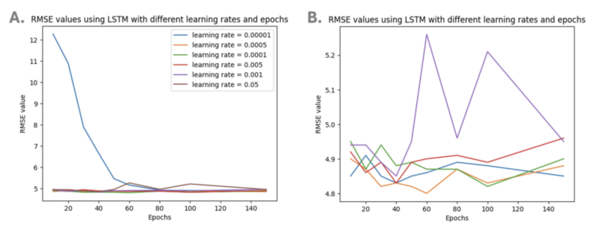
Although there has been great progress in the field of Natural language processing (NLP) over the last few years, particularly with the development of attention-based models, less research has contributed towards modeling keystroke log data. State of the art methods handle textual data directly and while this has produced excellent results, the time complexity and resource usage are quite high for such methods. Additionally, these methods fail to incorporate the actual writing process when assessing text and instead solely focus on the content. Therefore, we proposed a framework for modeling textual data using keystroke-based features. Such methods pay attention to how a document or response was written, rather than the final text that was produced. These features are vastly different from the kind of features extracted from raw text but reveal information that is otherwise hidden. We hypothesized that pairing efficient machine learning techniques with keystroke log information should produce results comparable to transformer techniques, models which pay more or less attention to the different components of a text sequence in a far quicker time. Transformer-based methods dominate the field of NLP currently due to the strong understanding they display of natural language. We showed that models trained on keystroke log data are capable of effectively evaluating the quality of writing and do it in a significantly shorter amount of time compared to traditional methods. This is significant as it provides a necessary fast and cheap alternative to increasingly larger and slower LLMs.
Read More...Using Artificial Intelligence to Forecast Continuous Glucose Monitor(CGM) readings for Type One Diabetes
People with Type One diabetes often rely on Continuous Blood Glucose Monitors (CGMs) to track their blood glucose and manage their condition. Researchers are now working to help people with Type One diabetes more easily monitor their health by developing models that will future blood glucose levels based on CGM readings. Jalla and Ghanta tackle this issue by exploring the use of AI models to forecast blood glucose levels with CGM data.
Read More...Studying the effects of different anesthetics on quasi-periodic patterns in rat fMRI
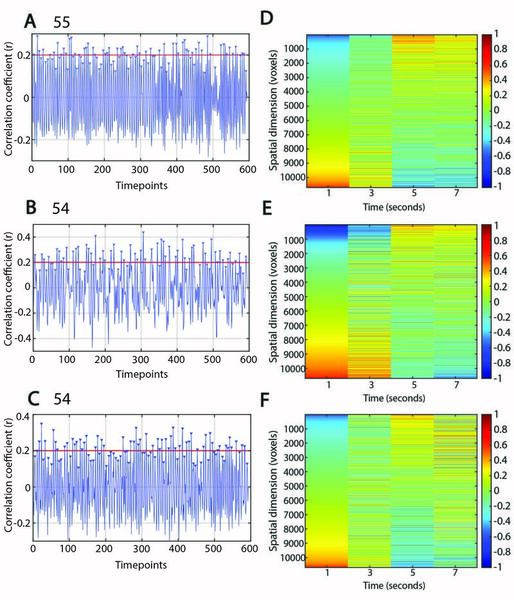
The authors looked at the effects of commonly used anesthetics in rodents on brain activity (specifically quasi-periodic patterns). Understanding effects on brain activity is important for researchers to understand when choosing rodent models for disease.
Read More...Using two-stage deep learning to assist the visually impaired with currency differentiation

Here, recognizing the difficulty that visually impaired people may have differentiating United States currency, the authors sought to use artificial intelligence (AI) models to identify US currencies. With a one-stage AI they reported a test accuracy of 89%, finding that multi-level deep learning models did not provide any significant advantage over a single-level AI.
Read More...Modeling Hartree-Fock approximations of the Schrödinger Equation for multielectron atoms from Helium to Xenon using STO-nG basis sets
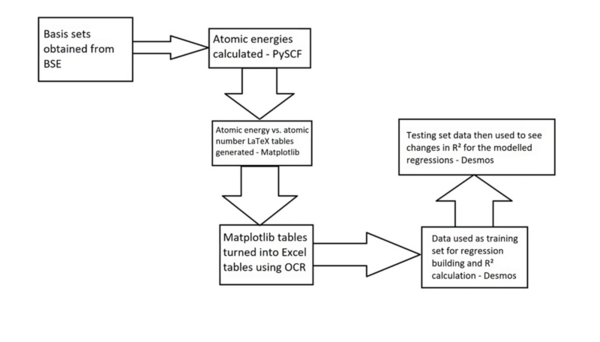
The energy of an atom is extremely useful in nuclear physics and reaction mechanism pathway determination but is challenging to compute. This work aimed to synthesize regression models for Pople Gaussian expansions of Slater-type Orbitals (STO-nG) atomic energy vs. atomic number scatter plots to allow for easy approximation of atomic energies without using computational chemistry methods. The data indicated that of the regressions, sinusoidal regressions most aptly modeled the scatter plots.
Read More...