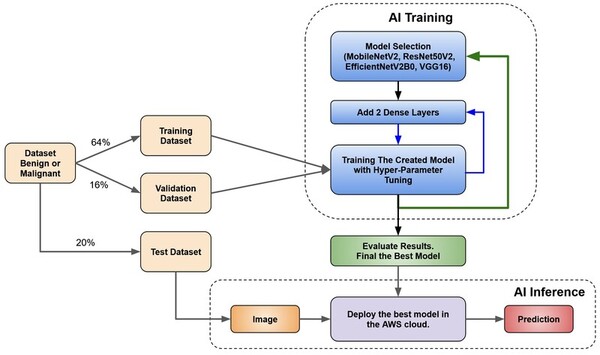
Skin cancer is a common and potentially deadly form of cancer. This study’s purpose was to develop an automated approach for early detection for skin cancer. We hypothesized that convolutional neural network-based models using transfer learning could accurately differentiate between benign and malignant moles using natural images of human skin.
Autism spectrum disorder (ASD) is hard to correctly diagnose due to the very subjective nature of diagnosing it: behavior analysis. Due to this issue, we sought to find a machine learning-based method that diagnoses ASD without behavior analysis or helps reduce misdiagnosis.
Image credit: Chunduri, Srinivas and McMahan, 2024.
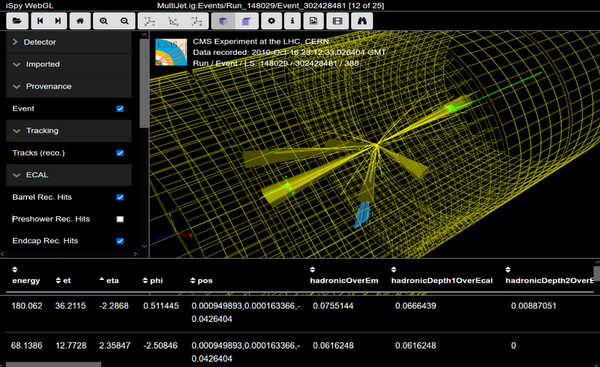
Collisions of heavy ions, such as muons result in jets and noise. In high-energy particle physics, researchers use jets as crucial event-shaped observable objects to determine the properties of a collision. However, many ionic collisions result in large amounts of energy lost as noise, thus reducing the efficiency of collisions with heavy ions. The purpose of our study is to analyze the relationships between properties of muons in a dimuon collision to optimize conditions of dimuon collisions and minimize the noise lost. We used principles of Newtonian mechanics at the particle level, allowing us to further analyze different models. We used simple Python algorithms as well as linear regression models with tools such as sci-kit Learn, NumPy, and Pandas to help analyze our results. We hypothesized that since the invariant mass, the energy, and the resultant momentum vector are correlated with noise, if we constrain these inputs optimally, there will be scenarios in which the noise of the heavy-ion collision is minimized.
Middle school math forms the basis for advanced mathematical courses leading up to the university level. Large language models (LLMs) have the potential to power next-generation educational technologies, acting as digital tutors to students. The main objective of this study was to determine whether LLMs like ChatGPT, Bard, and Llama 2 can serve as reliable middle school math tutoring assistants on three tutoring tasks: hint generation, comprehensive solution, and exercise creation.
We systematically evaluated the effects of raw material composition, heat treatment, and mechanical properties on 13-8PH stainless steel alloy. The results of the neural network models were in agreement with experimental results and aided in the evaluation of the effects of aging temperature on double shear strength. The data suggests that this model can be used to determine the appropriate 13-8PH alloy aging temperature needed to achieve the desired mechanical properties, eliminating the need for many costly trials and errors through re-heat treatments.
While resources on the safety of household cleaning products are plentiful, measures of efficacy of these cleaning chemicals against bacteria and viruses remain without standardization in the consumer market. The COVID pandemic has exasperated this knowledge gap, stoking the growth of misinformation and misuse surrounding household cleaning chemicals. Arriving at a time dire for sanitization standardization, the authors of this paper have created a quantifying framework for consumers by comparing a wide range of household cleaning products in their efficacy against bacteria generated by a safe and easily replicable yogurt model.
Here, seeking to understand the correlation of 50 of the most important economic indicators with inflation, the authors used a rolling linear regression to identify indicators with the most significant correlation with the Month over Month Consumer Price Index Seasonally Adjusted (CPI). Ultimately the concluded that the average gasoline price, U.S. import price index, and 5-year market expected inflation had the most significant correlation with the CPI.
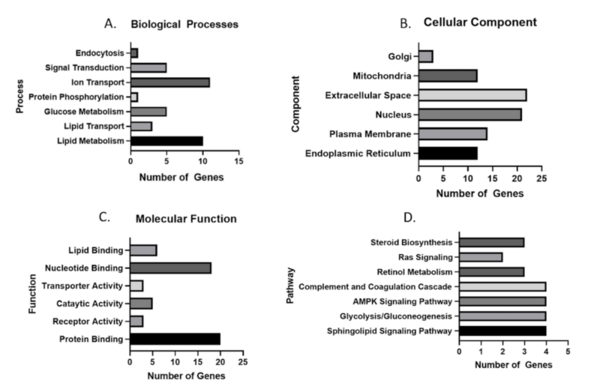
In this study, the authors analyze gene expression datasets to determine if there is a core set of genes dysregulated during nonalcoholic steatohepatitis.
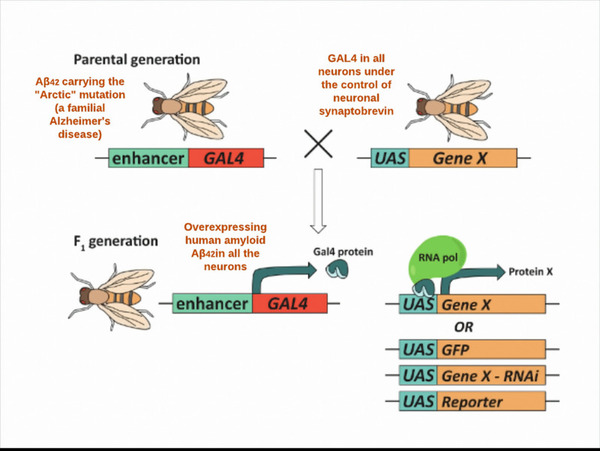
Oxidative damage and neuro-inflammation were the key pathways implicated in the pathogenesis of Alzheimer’s disease. In this study, 30 natural extracts from plant roots and leaves with extensive anti-inflammatory and anti-oxidative properties were consumed by Drosophila melanogaster. Several assays were performed to evaluate the efficacy of these combinational extracts on delaying the progression of Alzheimer’s disease. The experimental group showed increased motor activity, improved associative memory, and decreased lifespan decline relative to the control group.
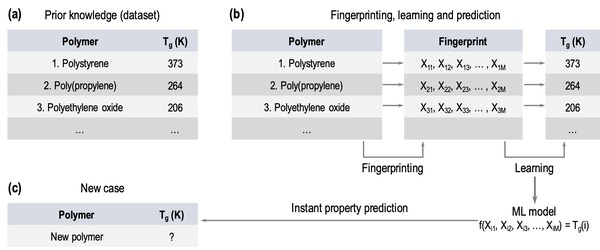
In this study, the authors test whether providing a larger dataset of glass transition temperatures (Tg) to train the machine-learning platform Polymer Genome would improve its accuracy. Polymer Genome is a machine learning based data-driven informatics platform for polymer property prediction and Tg is one property needed to design new polymers in silico. They found that training the model with their larger, curated dataset improved the algorithm's Tg, providing valuable improvements to this useful platform.
.png)