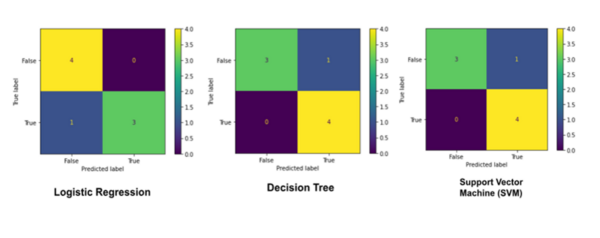
Here the authors hypothesized that reducing folliculin (FLCN) might affect p62 protein levels in the dorsal hippocampus of mice, given their potential functional connection and p62's role in neurodegenerative diseases. Their study, using western blots and a two-way ANOVA on young wild-type mice, found that p62 levels correlated with FLCN expression, but ultimately concluded there's no evidence of a functional connection between FLCN and p62 in this specific model.
Read More...
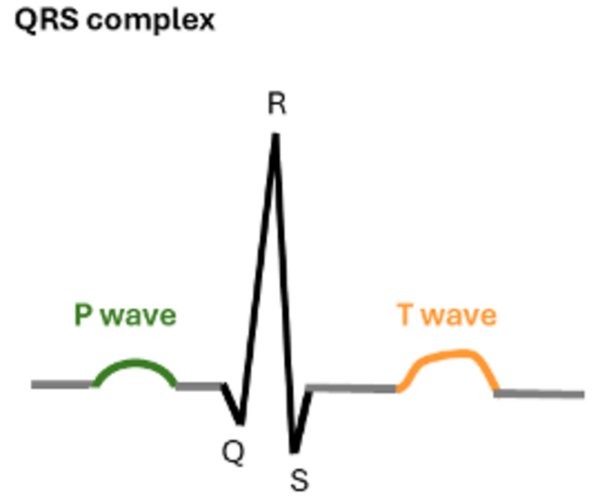

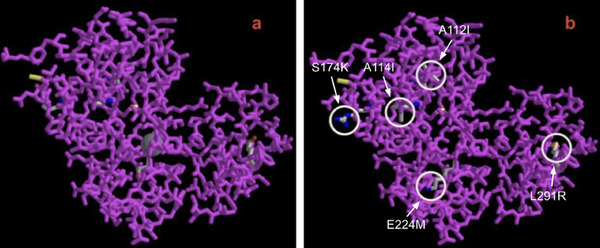
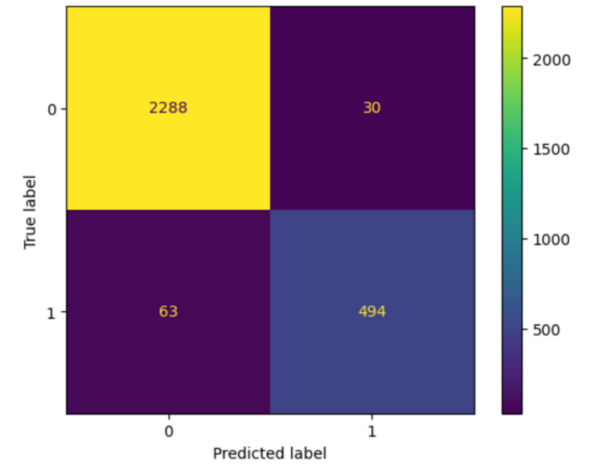

.png)