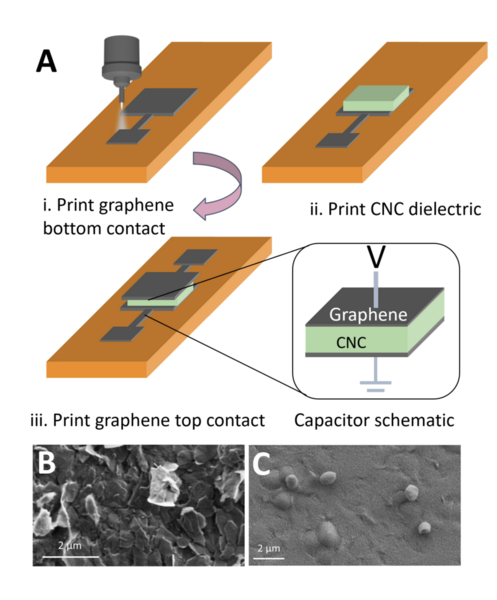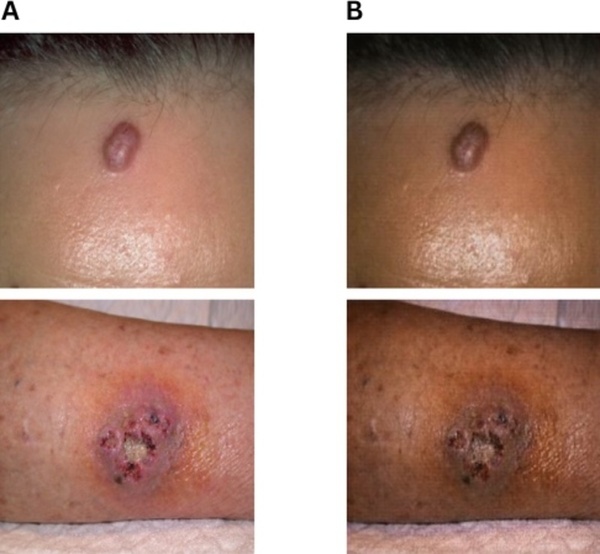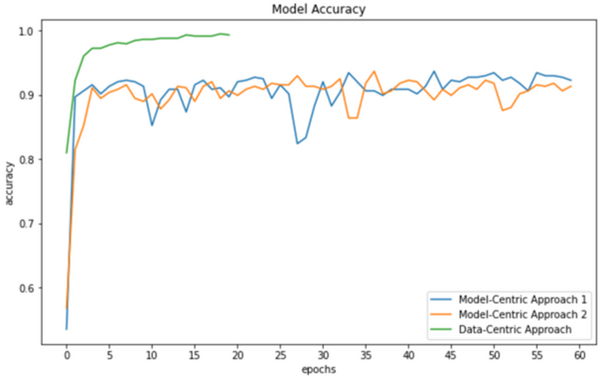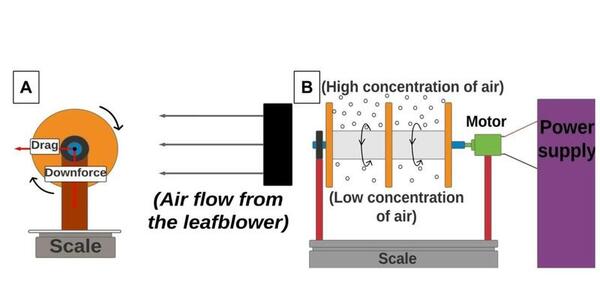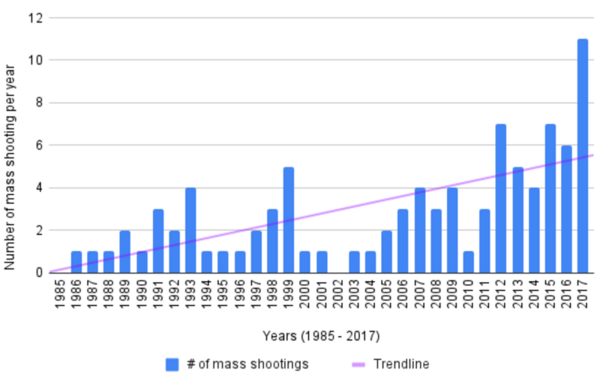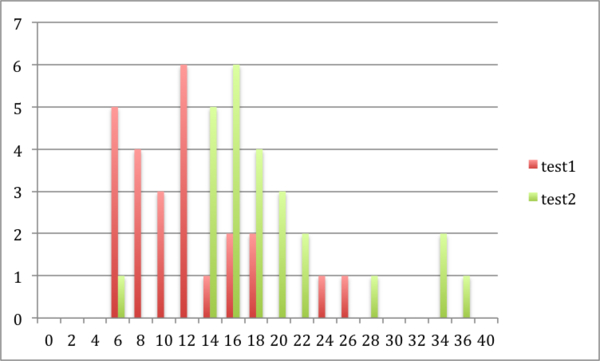
Playing video games may improve mental performance by encouraging practicing logical reasoning skills. Students who played video games in between two tests tended to perform better on the second test than those that did not play video games.
Read More...