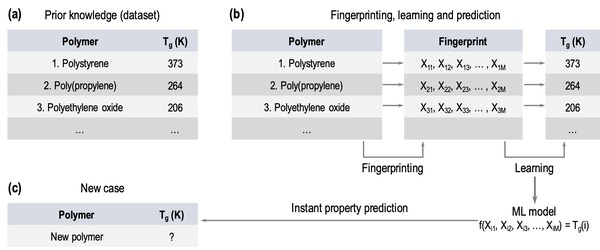
In this study, the authors test whether providing a larger dataset of glass transition temperatures (Tg) to train the machine-learning platform Polymer Genome would improve its accuracy. Polymer Genome is a machine learning based data-driven informatics platform for polymer property prediction and Tg is one property needed to design new polymers in silico. They found that training the model with their larger, curated dataset improved the algorithm's Tg, providing valuable improvements to this useful platform.
Read More...