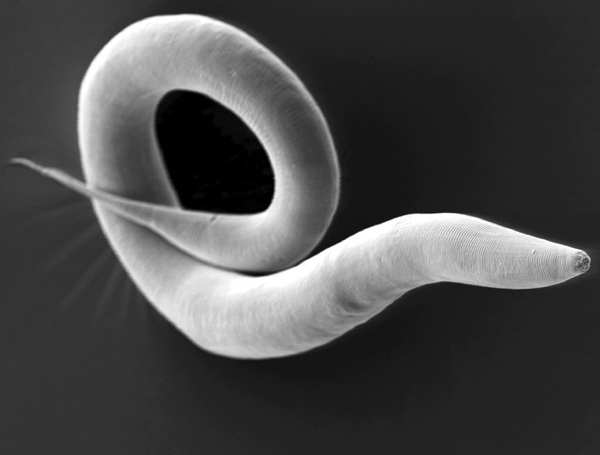
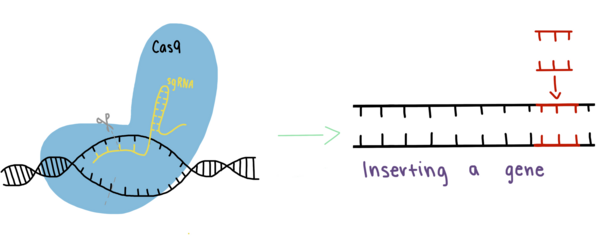
Cilia are little hair-like protrusions on many cells in the human body, including those lining the trachea where they play a role in clearing our respiratory tract of mucous and other irritants. Genetic mutations that impair ciliary function have serious consequences on our well-being making it important to understand how ciliary function is regulated. By using a simple organism, such as the worm C. elegans that use cilia to move, the authors explore the effect of certain genetic mutations on the cilia of the worms by measuring their ability to move towards or away from certain odorants.
Although the United States maintains millions of square kilometers of nature reserves to protect the biodiversity of the specimens living there, little is known about how confining these species within designated protected lands influences the genetic variation required for a healthy population. In this study, the authors sequenced genetic barcodes of insects from a recently established nature reserve, the Southwestern Riverside County Multi-Species Reserve (SWRCMSR), and a non-protected area, the Mt. San Jacinto College (MSJC) Menifee campus, to compare the genetic variation between the two populations. Their results demonstrated that the midge fly population from the SWRCMSR had fewer unique DNA barcode sequence changes than the MSJC population, indicating that the comparatively younger nature reserve's population had likely not yet established its own unique genetic drift changes.
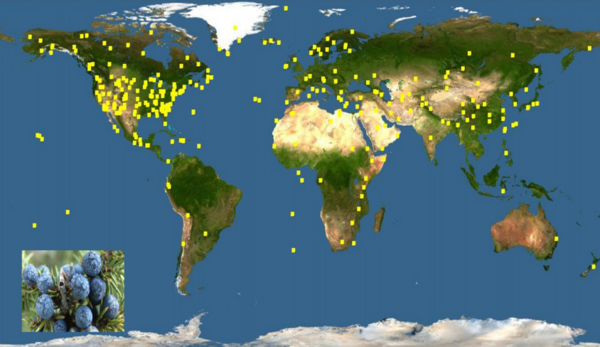
Many species of trees are distributed widely around the world, though not always in a way that makes immediate sense. The authors here use genetic information to help explain the geographic distribution of various conifer species throughout the world.
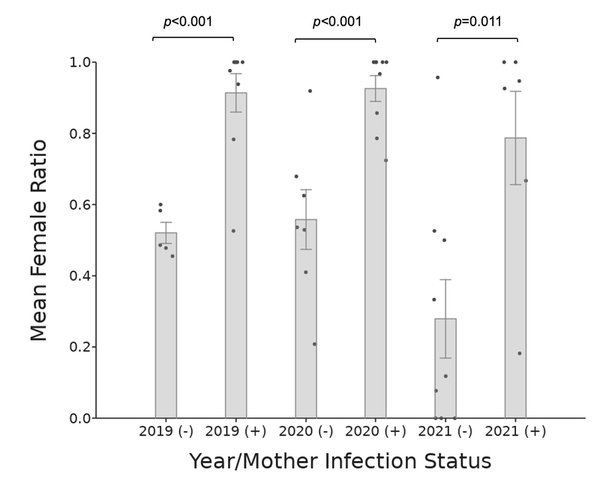
Wolbachia pipientis (Wolbachia) is a maternally inherited endosymbiotic bacterium that infects over 50% of arthropods, including pillbugs, and acts as a reproductive parasite in the host. In the common terrestrial pillbug Armadillidium vulgare (A. vulgare), Wolbachia alters the sex ratio of offspring through a phenomenon called feminization, where genetic males develop into reproductive females. Previous studies have focused on the presence or absence of Wolbachia as a sex ratio distorter in laboratory cultured and natural populations mainly from sites in Europe and Japan. Our three-year study is the first to evaluate the effects of the Wolbachia sex ratio distorter in cultured A. vulgare offspring in North America. We asked whether Wolbachia bacteria feminize A. vulgare isopod male offspring from infected mothers and if this effect can be detected in F1 offspring by comparing the male/female offspring ratios. If so, the F1 offspring ratio should show a higher number of females than males compared to the offspring of uninfected mothers. Over three years, pillbug offspring were cultured from pregnant A. vulgare females and developed into adults. We determined the Wolbachia status of mothers and counted the ratios of male and female F1 progeny to determine feminization effects. In each year sampled, significantly more female offspring were born to Wolbachia-infected mothers than those from uninfected mothers. These ratio differences suggest that the Wolbachia infection status of mothers directly impacts the A. vulgare population through the production of reproductive feminized males, which in turn provides an advantage for further Wolbachia transmission.
Breast cancer is the most common cancer in women, with approximately 300,000 diagnosed with breast cancer in 2023. It ranks second in cancer-related deaths for women, after lung cancer with nearly 50,000 deaths. Scientists have identified important genetic mutations in genes like BRCA1 and BRCA2 that lead to the development of breast cancer, but previous studies were limited as they focused on specific populations. To overcome limitations, diverse populations and powerful statistical methods like genome-wide association studies and whole-genome sequencing are needed. Explainable artificial intelligence (XAI) can be used in oncology and breast cancer research to overcome these limitations of specificity as it can analyze datasets of diagnosed patients by providing interpretable explanations for identified patterns and predictions. This project aims to achieve technological and medicinal goals by using advanced algorithms to identify breast cancer subtypes for faster diagnoses. Multiple methods were utilized to develop an efficient algorithm. We hypothesized that an XAI approach would be best as it can assign scores to genes, specifically with a 90% success rate. To test that, we ran multiple trials utilizing XAI methods through the identification of class-specific and patient-specific key genes. We found that the study demonstrated a pipeline that combines multiple XAI techniques to identify potential biomarker genes for breast cancer with a 95% success rate.
Sequence accessibility is an important factor affecting gene expression. Sequence accessibility or openness impacts the likelihood that a gene is transcribed and translated into a protein and performs functions and manifests traits. There are many potential factors that affect the accessibility of a gene. In this study, our hypothesis was that the content of nucleotides in a genetic sequence predicts its accessibility. Using a machine learning linear regression model, we studied the relationship between nucleotide content and accessibility.
Alzheimer's disease is one of the leading causes of death in the United States and is characterized by neurodegeneration. Mishra et al. wanted to understand the role of two transport proteins, LRP1 and AQP4, in the neurodegeneration of Alzheimer's disease. They used a model organism for Alzheimer's disease, the nematode C. elegans, and genetic engineering to look at whether they would see a decrease in neurodegeneration if they increased the amount of these two transport proteins. They found that the best improvements were caused by increased expression of both transport proteins, with smaller improvements when just one of the proteins is overly expressed. Their work has important implications for how we understand neurodegeneration in Alzheimer's disease and what we can do to slow or prevent the progression of the disease.
Given an association between nicotine addiction and gene expression, we hypothesized that expression of genes commonly associated with smoking status would have variable expression between smokers and non-smokers. To test whether gene expression varies between smokers and non-smokers, we analyzed two publicly-available datasets that profiled RNA gene expression from brain (nucleus accumbens) and lung tissue taken from patients identified as smokers or non-smokers. We discovered statistically significant differences in expression of dozens of genes between smokers and non-smokers. To test whether gene expression can be used to predict whether a patient is a smoker or non-smoker, we used gene expression as the training data for a logistic regression or random forest classification model. The random forest classifier trained on lung tissue data showed the most robust results, with area under curve (AUC) values consistently between 0.82 and 0.93. Both models trained on nucleus accumbens data had poorer performance, with AUC values consistently between 0.65 and 0.7 when using random forest. These results suggest gene expression can be used to predict smoking status using traditional machine learning models. Additionally, based on our random forest model, we proposed KCNJ3 and TXLNGY as two candidate markers of smoking status. These findings, coupled with other genes identified in this study, present promising avenues for advancing applications related to the genetic foundation of smoking-related characteristics.
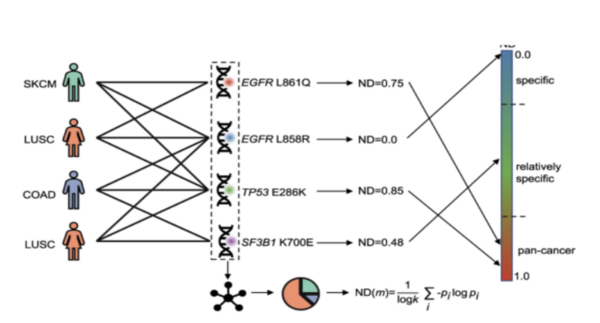
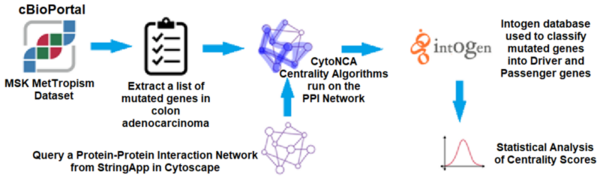
In this article the authors created an interaction map of proteins involved in colorectal cancer to look for driver vs. non-driver genes. That is they wanted to see if they could determine what genes are more likely to drive the development and progression in colorectal cancer and which are present in altered states but not necessarily driving disease progression.