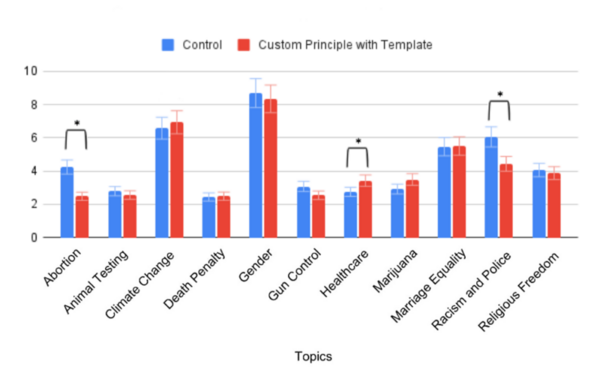
Various methods exist to mitigate bias in AI models, including "Constitutional AI," a technique which guides the AI to behave according to a list of rules and principles. Lo, Poosarla, Singhal, Li, Fu, and Mui investigate whether constitutional AI can reduce bias in AI outputs on political topics.
Read More...