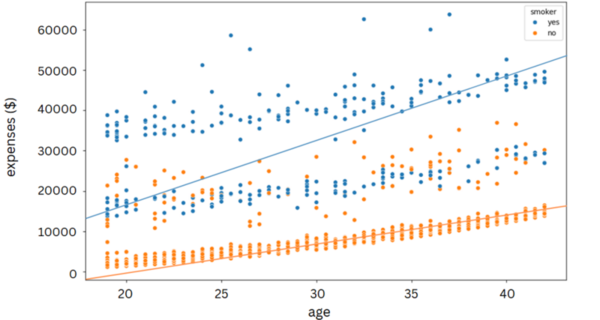
The authors looked at different factors, such as age, pre-existing conditions, and geographic region, and their ability to predict what an individual's health insurance premium would be.
Read More...Deep dive into predicting insurance premiums using machine learning
The authors looked at different factors, such as age, pre-existing conditions, and geographic region, and their ability to predict what an individual's health insurance premium would be.
Read More...A Novel Model to Predict a Book's Success in the New York Times Best Sellers List

In this article, the authors identify the characteristics that make a book a best-seller. Knowing what, besides content, predicts the success of a book can help publishers maximize the success of their print products.
Read More...Transfer Learning with Convolutional Neural Network-Based Models for Skin Cancer Classification
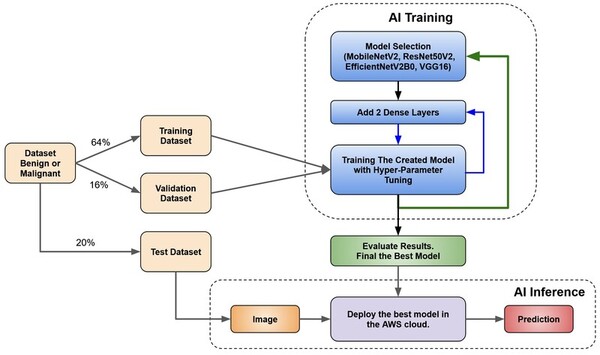
Skin cancer is a common and potentially deadly form of cancer. This study’s purpose was to develop an automated approach for early detection for skin cancer. We hypothesized that convolutional neural network-based models using transfer learning could accurately differentiate between benign and malignant moles using natural images of human skin.
Read More...Using text embedding models as text classifiers with medical data

This article describes the classification of medical text data using vector databases and text embedding. Various large language models were used to generate this medical data for the classification task.
Read More...Assessing machine learning model efficacy for brain tumor MRI classification: a multi-model approach
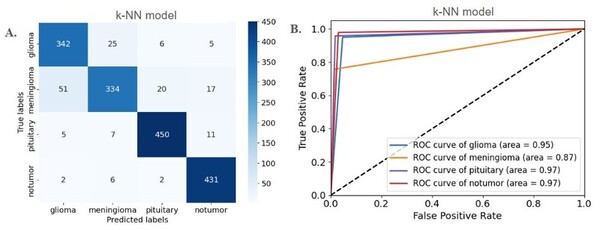
This manuscript explores the performance of five different machine learning models in classifying brain tumors from a dataset of MRI scans. The authors find that several of the models showed >90% accuracy. Thus, the authors suggest that machine learning models demonstrate potential for effective implementation in clinical settings, including as a diagnostic tool that can be used to complement the expertise of neuroradiologists.
Read More...Quantitative analysis and development of alopecia areata classification frameworks
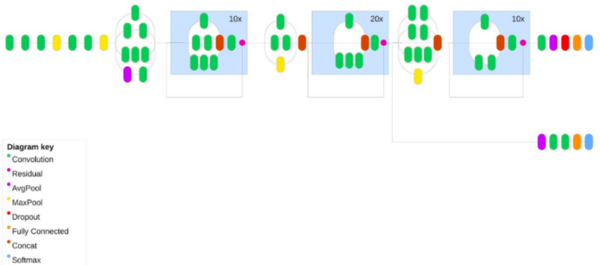
This article discusses Alopecia areata, an autoimmune disorder causing sudden hair loss due to the immune system mistakenly attacking hair follicles. The article introduces the use of deep learning (DL) techniques, particularly convolutional neural networks (CNN), for classifying images of healthy and alopecia-affected hair. The study presents a comparative analysis of newly optimized CNN models with existing ones, trained on datasets containing images of healthy and alopecia-affected hair. The Inception-Resnet-v2 model emerged as the most effective for classifying Alopecia Areata.
Read More...Feature extraction from peak detection algorithms for enhanced EMG-based hand gesture recognition models
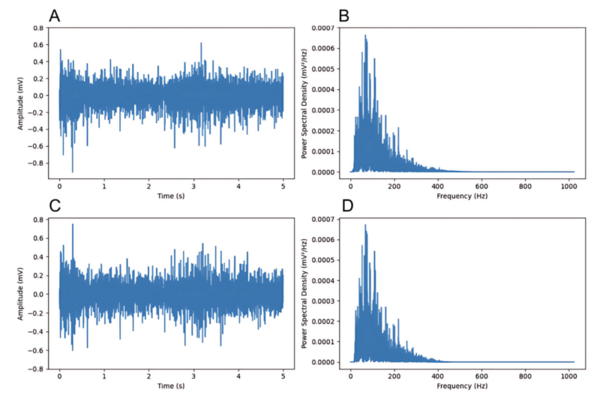
This manuscript evaluates peak detection algorithms for feature extraction in EMG-based hand gesture recognition using a random forest classifier. The study demonstrates that wavelet-based peak detection features achieve the highest classification accuracy (96.5%), outperforming other methods. The results highlight the potential of peak features to improve EMG-based prosthetic control systems.
Read More...Collaboration beats heterogeneity: Improving federated learning-based waste classification

Based on the success of deep learning, recent works have attempted to develop a waste classification model using deep neural networks. This work presents federated learning (FL) for a solution, as it allows participants to aid in training the model using their own data. Results showed that with less clients, having a higher participation ratio resulted in less accuracy degradation by the data heterogeneity.
Read More...Explainable AI tools provide meaningful insight into rationale for prediction in machine learning models
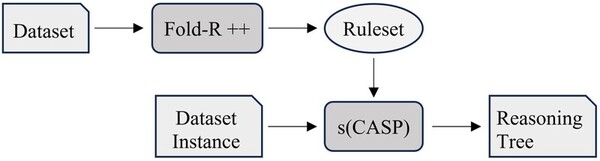
The authors compare current machine learning algorithms with a new Explainable AI algorithm that produces a human-comprehensible decision tree alongside predictions.
Read More...Impact of length of audio on music classification with deep learning
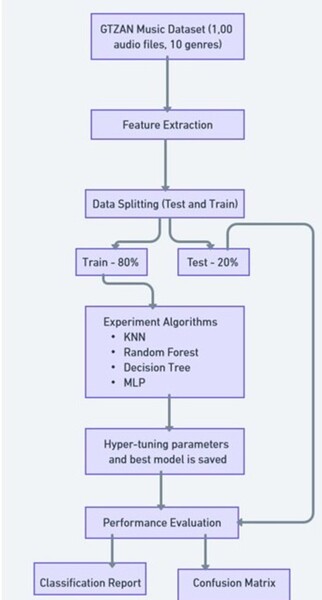
The authors looked at how the length of an audio clip used of a song impacted the ability to properly classify it by musical genre.
Read More...