
The authors looked at different algorithms and their ability to encrypt and decrypt text of various lengths.
Read More...Comparative analysis of the speeds of AES, ChaCha20, and Blowfish encryption algorithms
The authors looked at different algorithms and their ability to encrypt and decrypt text of various lengths.
Read More...Effects of noise on information corruption in the quantum teleportation algorithm
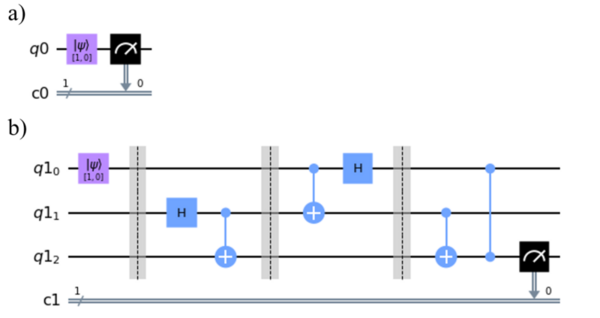
In quantum computing, noise disrupts experimental results, particularly affecting the quantum teleportation algorithm used to transfer qubit states. This study explores how noise impacts this algorithm across different platforms—a perfect simulation, a noisy simulation, and real hardware.
Read More...Solving the Schrödinger equation computationally using the Lanczos algorithm
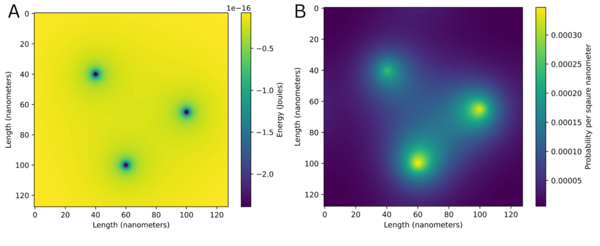
The authors use the Lanczos algorithm to computationally solve the Schrodinger equation for 2D potentials with a Python program
Read More...Optimizing Interplanetary Travel Using a Genetic Algorithm

In this work, the authors develop an algorithm that solves the problem of efficient space travel between planets. This is a problem that could soon be of relevance as mankind continues to expand its exploration of outer space, and potentially attempt to inhabit it.
Read More...DyGS: A Dynamic Gene Searching Algorithm for Cancer Detection
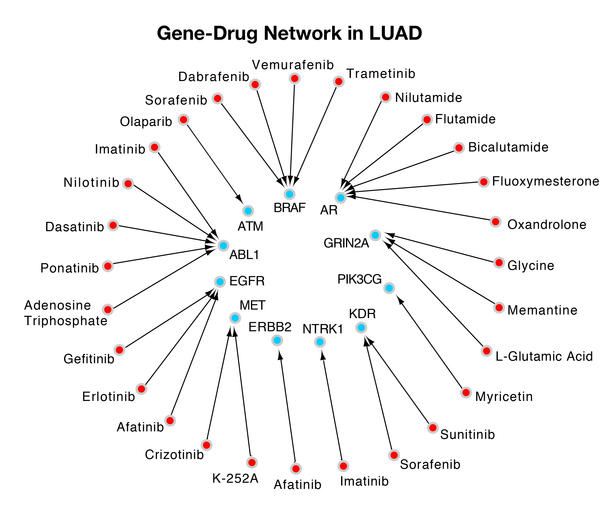
Wang and Gong developed a novel dynamic gene-searching algorithm called Dynamic Gene Search (DyGS) to create a gene panel for each of the 12 cancers with the highest annual incidence and death rate. The 12 gene panels the DyGS algorithm selected used only 3.5% of the original gene mutation pool, while covering every patient sample. About 40% of each gene panel is druggable, which indicates that the DyGS-generated gene panels can be used for early cancer detection as well as therapeutic targets in treatment methods.
Read More...Comparison of spectral subtraction noise reduction algorithms

Here, the authors investigated methods to reduce noise in audio composed of real-word sounds. They specifically used two spectral subtraction noise reduction algorithms: stationary and non-stationary finding notable differences in noise improvements depending on the noise sources.
Read More...A Quantitative Assessment of Time, Frequency, and Time-frequency Algorithms for Automated Seizure Detection and Monitoring
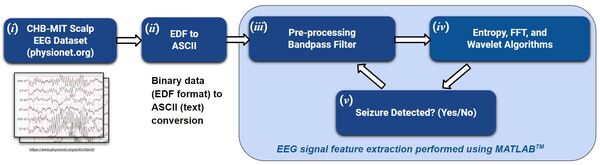
Each year, over 100,000 patients die from Sudden Unexpected Death in Epilepsy (SUDEP). A reliable seizure warning system can help patients stay safe. This work presents a comprehensive, comparative analysis of three different signal processing algorithms for automated seizure/ictal detection. The experimental results show that the proposed methods can be effective for accurate automated seizure detection and monitoring in clinical care.
Read More...Exploring the effects of diverse historical stock price data on the accuracy of stock price prediction models
Algorithmic trading has been increasingly used by Americans. In this work, we tested whether including the opening, closing, and highest prices in three supervised learning models affected their performance. Indeed, we found that including all three prices decreased the error of the prediction significantly.
Read More...Using data science along with machine learning to determine the ARIMA model’s ability to adjust to irregularities in the dataset

Auto-Regressive Integrated Moving Average (ARIMA) models are known for their influence and application on time series data. This statistical analysis model uses time series data to depict future trends or values: a key contributor to crime mapping algorithms. However, the models may not function to their true potential when analyzing data with many different patterns. In order to determine the potential of ARIMA models, our research will test the model on irregularities in the data. Our team hypothesizes that the ARIMA model will be able to adapt to the different irregularities in the data that do not correspond to a certain trend or pattern. Using crime theft data and an ARIMA model, we determined the results of the ARIMA model’s forecast and how the accuracy differed on different days with irregularities in crime.
Read More...A comparative analysis of machine learning approaches for prediction of breast cancer
Machine learning and deep learning techniques can be used to predict the early onset of breast cancer. The main objective of this analysis was to determine whether machine learning algorithms can be used to predict the onset of breast cancer with more than 90% accuracy. Based on research with supervised machine learning algorithms, Gaussian Naïve Bayes, K Nearest Algorithm, Random Forest, and Logistic Regression were considered because they offer a wide variety of classification methods and also provide high accuracy and performance. We hypothesized that all these algorithms would provide accurate results, and Random Forest and Logistic Regression would provide better accuracy and performance than Naïve Bayes and K Nearest Neighbor.
Read More...