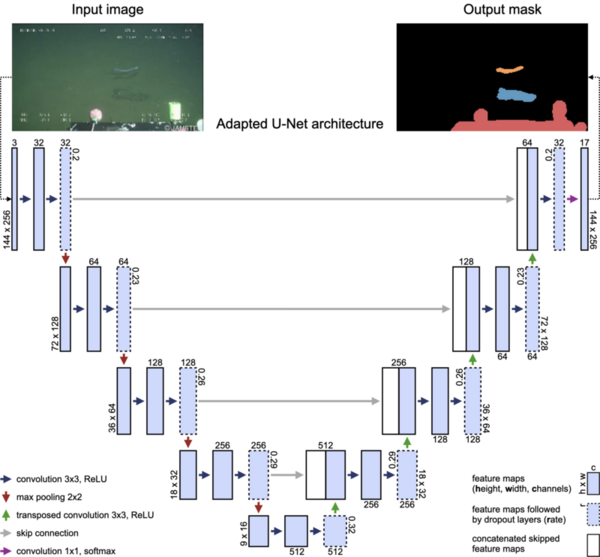
Plastic pollution in the ocean is a major global concern. Remotely Operated Vehicles (ROVs) have promise for removing debris from the ocean, but more research is needed to achieve full effectiveness of the ROV technology. Wahlig and Gonzales tackle this issue by developing a deep learning model to distinguish trash from the environment in ROV images.
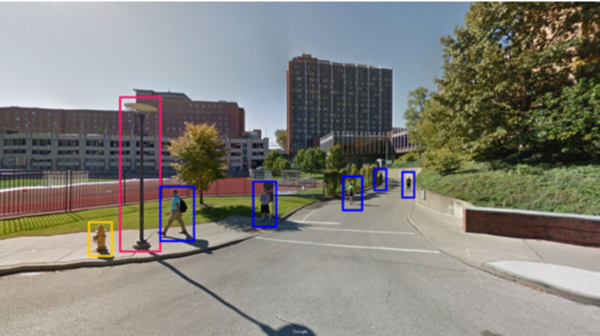
Every year, around 40% of undergraduate students in the United States discontinue their studies, resulting in a loss of valuable education for students and a loss of money for colleges. Even so, colleges across the nation struggle to discover the underlying causes of these high dropout rates. In this paper, the authors discuss the use of machine learning to find correlations between the built environment factors and the retention rates of colleges. They hypothesized that one way for colleges to improve their retention rates could be to improve the physical characteristics of their campus to be more pleasing. The authors used image classification techniques to look at images of colleges and correlate certain features like colors, cars, and people to higher or lower retention rates. With three possible options of high, medium, and low retention rates, the probability that their models reached the right conclusion if they simply chose randomly was 33%. After finding that this 33%, or 0.33 mark, always fell outside of the 99% confidence intervals built around their models’ accuracies, the authors concluded that their machine learning techniques can be used to find correlations between certain environmental factors and retention rates.
Based on the success of deep learning, recent works have attempted to develop a waste classification model using deep neural networks. This work presents federated learning (FL) for a solution, as it allows participants to aid in training the model using their own data. Results showed that with less clients, having a higher participation ratio resulted in less accuracy degradation by the data heterogeneity.
In this study, the authors surveyed a number of students in Singapore to determine how their experiences changed after the implementation of home-based learning during the COVID-19 pandemic.
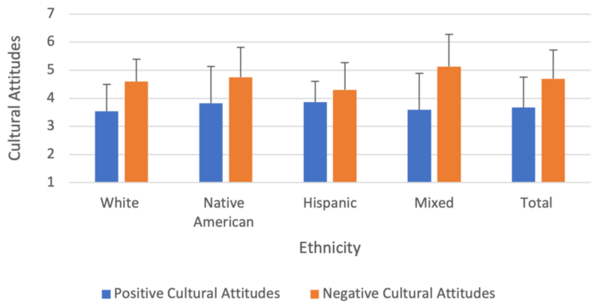
The authors looked at how a student's own background influence their attitude towards integration of diverse cultures and ethnicities. While overall students viewed other groups positively, the authors found that groups still indicated they felt judged by their peers.
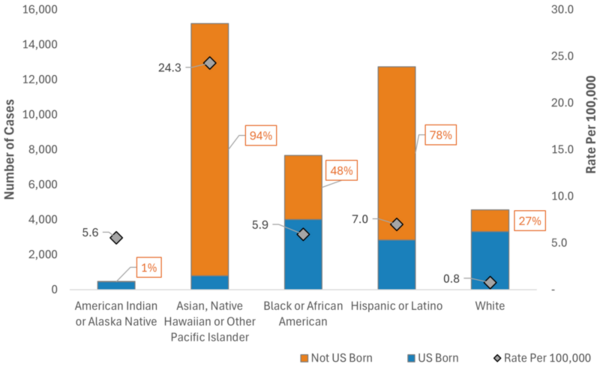
The main goal of this study is to determine what demographics are related to tuberculosis incidence in the United States populations, particularly if changing demographics are related to differences in tuberculosis risk over two discrete time periods. The major finding is that in the two studied time periods, tuberculosis risk factors were somewhat consistent and may be influenced by things such as immigration, healthcare access, and race or ethnicity, although the top predictor did change.
Given an association between nicotine addiction and gene expression, we hypothesized that expression of genes commonly associated with smoking status would have variable expression between smokers and non-smokers. To test whether gene expression varies between smokers and non-smokers, we analyzed two publicly-available datasets that profiled RNA gene expression from brain (nucleus accumbens) and lung tissue taken from patients identified as smokers or non-smokers. We discovered statistically significant differences in expression of dozens of genes between smokers and non-smokers. To test whether gene expression can be used to predict whether a patient is a smoker or non-smoker, we used gene expression as the training data for a logistic regression or random forest classification model. The random forest classifier trained on lung tissue data showed the most robust results, with area under curve (AUC) values consistently between 0.82 and 0.93. Both models trained on nucleus accumbens data had poorer performance, with AUC values consistently between 0.65 and 0.7 when using random forest. These results suggest gene expression can be used to predict smoking status using traditional machine learning models. Additionally, based on our random forest model, we proposed KCNJ3 and TXLNGY as two candidate markers of smoking status. These findings, coupled with other genes identified in this study, present promising avenues for advancing applications related to the genetic foundation of smoking-related characteristics.
A key barrier to adoption of solar energy technology is the low efficiency of solar cells converting solar energy into electricity. Sims and Sims tackle this problem by coding a Raspberry Pi as a multimeter to determine which wavelength of light generates the most voltage and current from a solar panel.
Sequence accessibility is an important factor affecting gene expression. Sequence accessibility or openness impacts the likelihood that a gene is transcribed and translated into a protein and performs functions and manifests traits. There are many potential factors that affect the accessibility of a gene. In this study, our hypothesis was that the content of nucleotides in a genetic sequence predicts its accessibility. Using a machine learning linear regression model, we studied the relationship between nucleotide content and accessibility.




.jpg)
