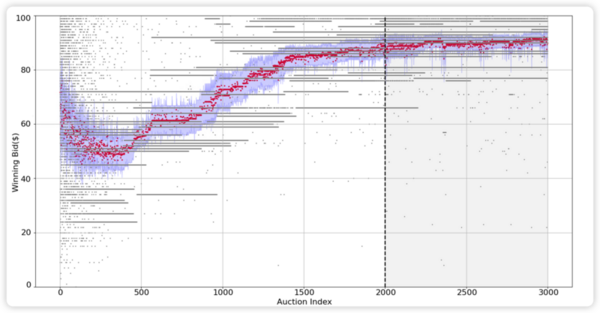
Advertising platforms like Google Ads use AI to drive the algorithms used to maximize advertisers benefits. This study shows that AI does not adjust it strategy based on auction type and highlights the limitations of AI running without explicit guidance.
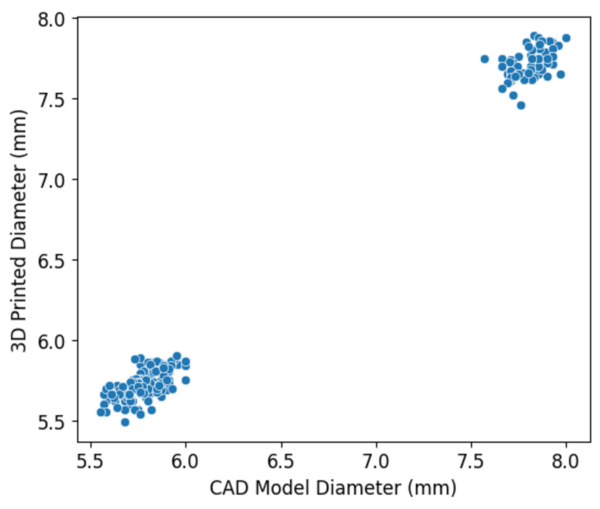
This study explores how to predict and minimize distortion in 3D printed parts, particularly when using affordable PLA filament. The researchers developed a model using a gradient boosting regressor trained on 3D printing data, aiming to predict the necessary CAD dimensions to counteract print distortion.
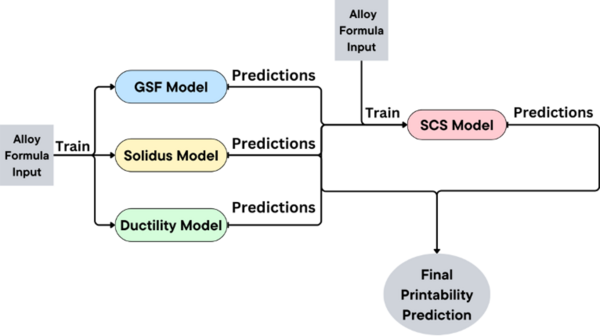
Additive manufacturing (AM) is transforming the production of complex metal parts, but challenges like internal cracking can arise, particularly in critical sectors such as aerospace and automotive. Traditional methods to assess cracking susceptibility are costly and time-consuming, prompting the use of machine learning (ML) for more efficient predictions. This study developed a multi-model ML pipeline that predicts solidification cracking susceptibility (SCS) more accurately by considering secondary alloy properties alongside composition, with Random Forest models showing the best performance, highlighting a promising direction for future research into SCS quantification.
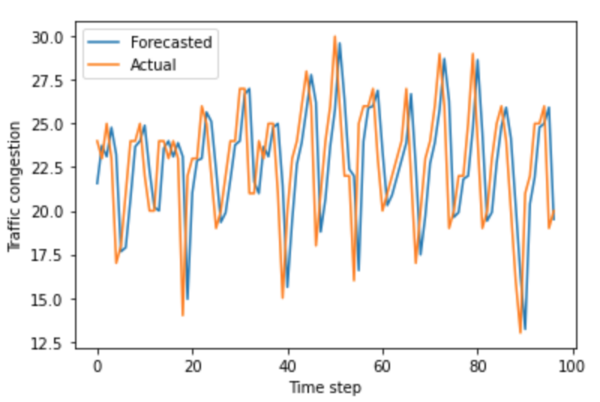
In this paper, we measured the privacy budgets and utilities of different differentially private mechanisms combined with different machine learning models that forecast traffic congestion at future timestamps. We expected the ANNs combined with the Staircase mechanism to perform the best with every value in the privacy budget range, especially with the medium high values of the privacy budget. In this study, we used the Autoregressive Integrated Moving Average (ARIMA) and neural network models to forecast and then added differentially private Laplacian, Gaussian, and Staircase noise to our datasets. We tested two real traffic congestion datasets, experimented with the different models, and examined their utility for different privacy budgets. We found that a favorable combination for this application was neural networks with the Staircase mechanism. Our findings identify the optimal models when dealing with tricky time series forecasting and can be used in non-traffic applications like disease tracking and population growth.
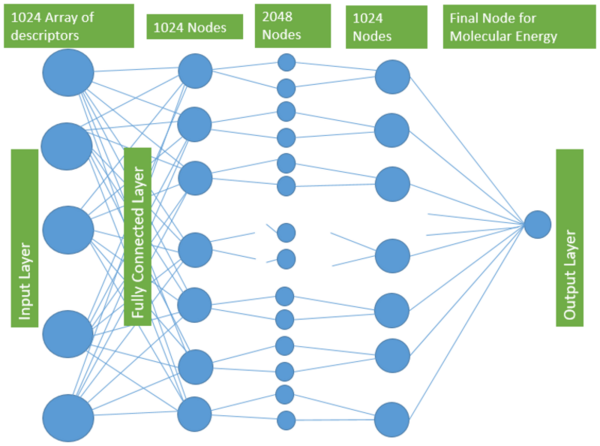
With molecular energy being an integral element to the study of molecules and molecular interactions, computational methods to determine molecular energy are used for the preservation of time and resources. However, these computational methods have high demand for computer resources, limiting their widespread feasibility. The authors of this study employed machine learning to address this disadvantage, utilizing neural networks trained on different representations of molecules to predict molecular properties without the requirement of computationally-intensive processing. In their findings, the authors determined the Feedforward Neural Network, trained by two separate models, as capable of predicting molecular energy with limited prediction error.
Auto-Regressive Integrated Moving Average (ARIMA) models are known for their influence and application on time series data. This statistical analysis model uses time series data to depict future trends or values: a key contributor to crime mapping algorithms. However, the models may not function to their true potential when analyzing data with many different patterns. In order to determine the potential of ARIMA models, our research will test the model on irregularities in the data. Our team hypothesizes that the ARIMA model will be able to adapt to the different irregularities in the data that do not correspond to a certain trend or pattern. Using crime theft data and an ARIMA model, we determined the results of the ARIMA model’s forecast and how the accuracy differed on different days with irregularities in crime.
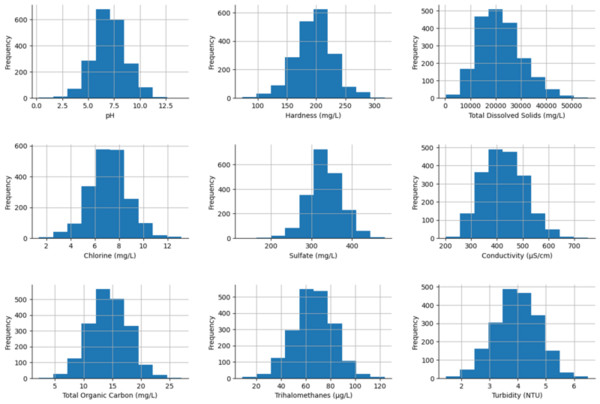
The global issue of water quality has led to the use of machine learning models, like ANN and SVM, to predict water potability. However, these models can be complex and resource-intensive. This research aimed to find a simpler, more efficient model for water quality prediction.
In this study the authors looked at the ability of artificial intelligence to detect tempo, rhythm, and intonation of a piece played on violin. Technology such as this would allow for students to practice and get feedback without the need of a teacher.
Here, seeking to identify an optimal method to classify tree species through remote sensing, the authors used a few machine learning algorithms to classify forest tree species through multispectral satellite imagery. They found the Random Forest algorithm to most accurately classify tree species, with the potential to improve model training and inference based on the inclusion of other tree properties.
Here, recognizing the recognizing the growing threat of non-biodegradable plastic waste, the authors investigated the ability to use a modified enzyme identified in bacteria to decompose polyethylene terephthalate (PET). They used simulations to screen and identify an optimized enzyme based on machine learning models. Ultimately, they identified a potential mutant PETases capable of decomposing PET with improved thermal stability.