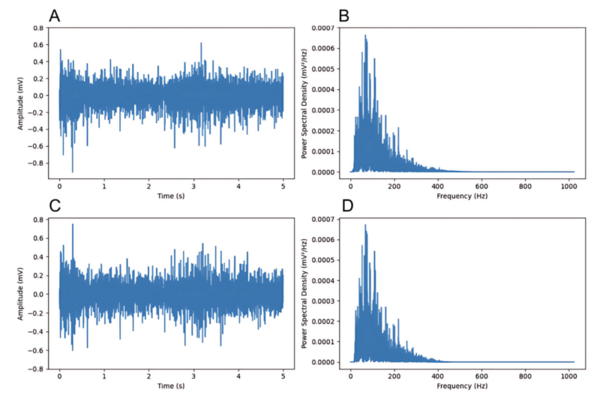
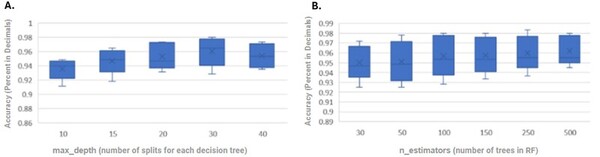
This manuscript evaluates peak detection algorithms for feature extraction in EMG-based hand gesture recognition using a random forest classifier. The study demonstrates that wavelet-based peak detection features achieve the highest classification accuracy (96.5%), outperforming other methods. The results highlight the potential of peak features to improve EMG-based prosthetic control systems.
Given an association between nicotine addiction and gene expression, we hypothesized that expression of genes commonly associated with smoking status would have variable expression between smokers and non-smokers. To test whether gene expression varies between smokers and non-smokers, we analyzed two publicly-available datasets that profiled RNA gene expression from brain (nucleus accumbens) and lung tissue taken from patients identified as smokers or non-smokers. We discovered statistically significant differences in expression of dozens of genes between smokers and non-smokers. To test whether gene expression can be used to predict whether a patient is a smoker or non-smoker, we used gene expression as the training data for a logistic regression or random forest classification model. The random forest classifier trained on lung tissue data showed the most robust results, with area under curve (AUC) values consistently between 0.82 and 0.93. Both models trained on nucleus accumbens data had poorer performance, with AUC values consistently between 0.65 and 0.7 when using random forest. These results suggest gene expression can be used to predict smoking status using traditional machine learning models. Additionally, based on our random forest model, we proposed KCNJ3 and TXLNGY as two candidate markers of smoking status. These findings, coupled with other genes identified in this study, present promising avenues for advancing applications related to the genetic foundation of smoking-related characteristics.
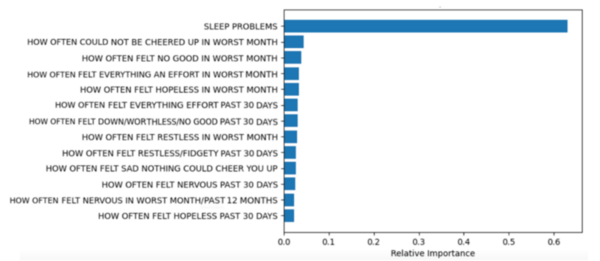
Sadly, around 800,000 people die by suicide worldwide each year. Dong and Pearce analyze health survey data to identify associations between suicidal ideation and relevant variables, such as sleep quality, hopelessness, and anxious behavior.
The authors combine fine needle aspiration biopsy and machine learning algorithms to develop a breast cancer detection method suitable for resource-constrained regions that lack access to mammograms.
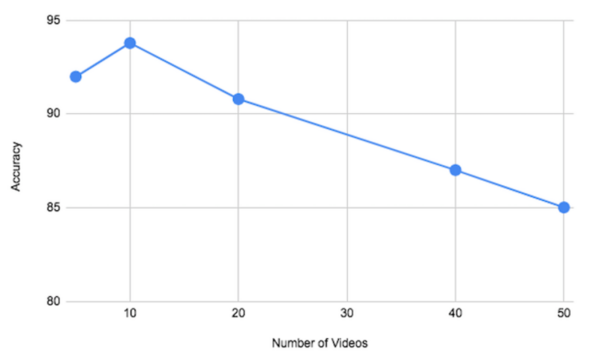
The Tor network allows individuals to secure their online identities by encrypting their traffic, however it is vulnerable to fingerprinting attacks that threaten users' online privacy. In this paper, the authors develop a new video fingerprinting model to explore how well video streaming can be fingerprinted in Tor. They found that their model could distinguish which one of 50 videos a user was hypothetically watching on the Tor network with 85% accuracy, demonstrating that video fingerprinting is a serious threat to the privacy of Tor users.
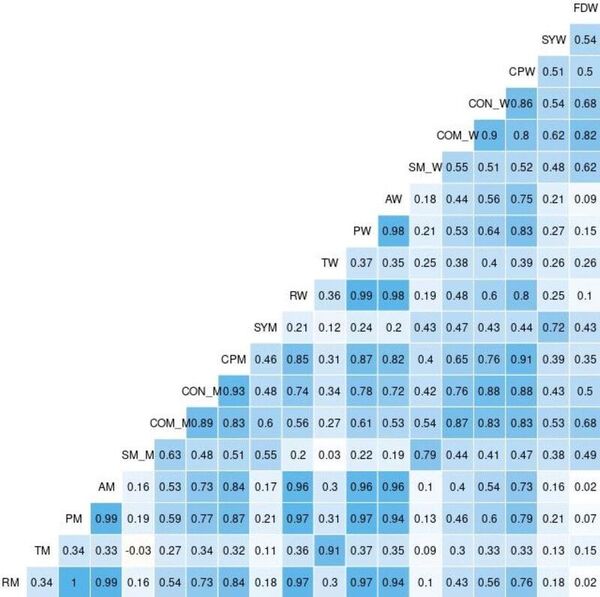
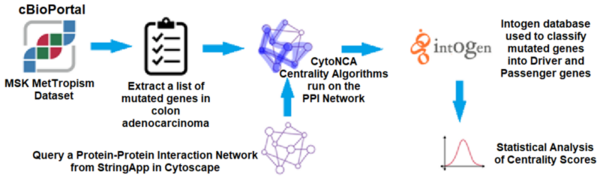
In this article the authors created an interaction map of proteins involved in colorectal cancer to look for driver vs. non-driver genes. That is they wanted to see if they could determine what genes are more likely to drive the development and progression in colorectal cancer and which are present in altered states but not necessarily driving disease progression.
In this article the authors looked at different attributes of apps within the Google Play store to determine how those may impact the overall app rating out of five stars. They found that review count, amount of storage needed and when the app was last updated to be the most influential factors on an app's rating.
Seeking to investigate the effects of ambient pollutants on human respiratory health, here the authors used machine learning to examine asthma in Lost Angeles County, an area with substantial pollution. By using machine learning models and classification techniques, the authors identified that nitrogen dioxide and ozone levels were significantly correlated with asthma hospitalizations. Based on an identified seasonal surge in asthma hospitalizations, the authors suggest future directions to improve machine learning modeling to investigate these relationships.
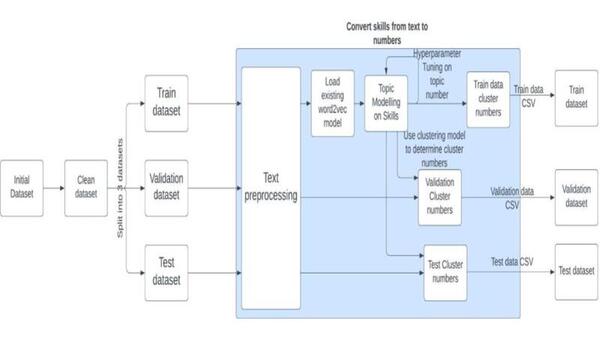
The authors looked at using machine learning to identify skills needed to apply for certain jobs, specifically looking at different techniques to parse apart the text. They found that Bidirectional Encoder Representation of Transforms (BERT) performed best.