
The authors looked at the dynamics of tennis serves from professional and amateur athletes.
Read More...Analysis of professional and amateur tennis serves using computer pose detection
The authors looked at the dynamics of tennis serves from professional and amateur athletes.
Read More...Artificial Intelligence-Based Smart Solution to Reduce Respiratory Problems Caused by Air Pollution

In this report, Bhardwaj and Sharma tested whether placing specific plants indoors can reduce levels of indoor air pollution that can lead to lung-related illnesses. Using machine learning, they show that plants improved overall indoor air quality and reduced levels of particulate matter. They suggest that plant-based interventions coupled with sensors may be a useful long-term solution to reducing and maintaining indoor air pollution.
Read More...Augmented Reality Chess Analyzer (ARChessAnalyzer): In-Device Inference of Physical Chess Game Positions through Board Segmentation and Piece Recognition using Convolutional Neural Networks
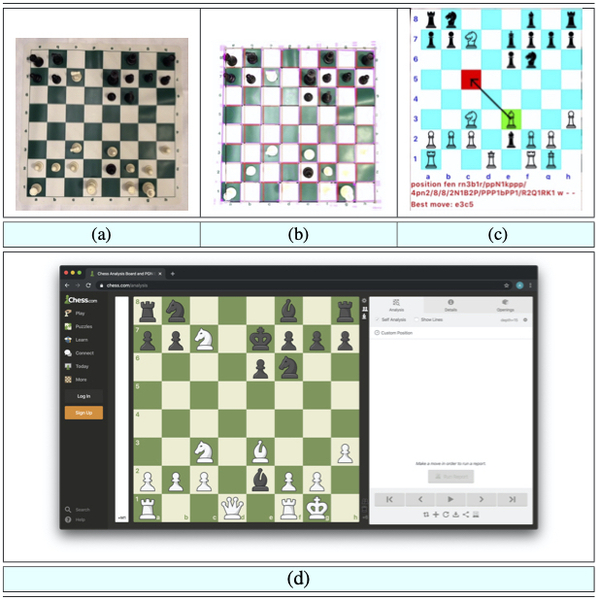
In this study the authors develop an app for faster chess game entry method to help chess learners improve their game. This culminated in the Augmented Reality Chess Analyzer (ARChessAnalyzer) which uses traditional image and vision techniques for chess board recognition and Convolutional Neural Networks (CNN) for chess piece recognition.
Read More...Towards multimodal longitudinal analysis for predicting cognitive decline

Understanding and predicting cognitive decline in Alzheimer's disease
Read More...Contribution of environmental factors to genetic variation in the Pacific white-sided dolphin

Here the authors sought to understand the effects of different variables that may be tied to pollution and climate change on genetic variation of Pacific white-sided dolphins, a species that is currently threatened by water pollution. Based on environmental data collected alongside a genetic distance matrix, they found that ocean currents had the most significant impact on the genetic diversity of Pacific white-sided dolphins along the Japanese coast.
Read More...Applying centrality analysis on a protein interaction network to predict colorectal cancer driver genes
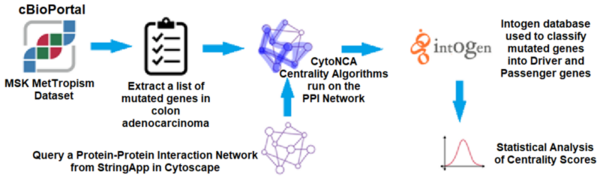
In this article the authors created an interaction map of proteins involved in colorectal cancer to look for driver vs. non-driver genes. That is they wanted to see if they could determine what genes are more likely to drive the development and progression in colorectal cancer and which are present in altered states but not necessarily driving disease progression.
Read More...Influence of socioeconomic status on academic performance in virtual classroom settings

In this study, the authors conduct a survey to evaluate the impact of household socioeconomic status on effectiveness of distance learning for students.
Read More...Effects of different synthetic training data on real test data for semantic segmentation

Semantic segmentation - labelling each pixel in an image to a specific class- models require large amounts of manually labeled and collected data to train.
Read More...AI-designed mini-protein targeting claudin-5 to enhance blood–brain barrier integrity
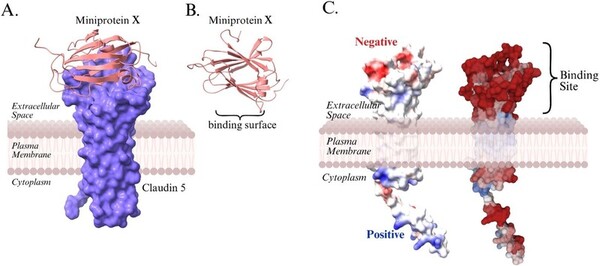
The authors employ computational protein design to identify a mini-protein with the potential to enhance binding of the tight junction protein, claudin-5, at the blood-blood barrier with therapeutic potential for neurodegenerative diseases.
Read More...Identifying anxiety and burnout from students facial expressions and demographics using machine learning
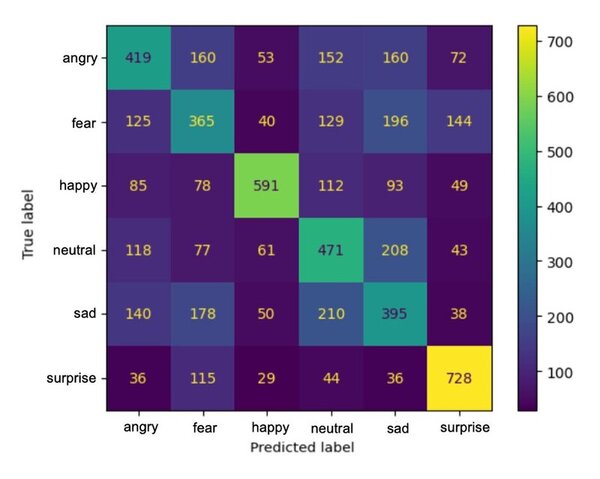
The authors used machine learning to predict the presence of anxiety and burnout in students based on facial expressions and demographic information.
Read More...