
Semantic segmentation - labelling each pixel in an image to a specific class- models require large amounts of manually labeled and collected data to train.
Read More...Effects of different synthetic training data on real test data for semantic segmentation
Semantic segmentation - labelling each pixel in an image to a specific class- models require large amounts of manually labeled and collected data to train.
Read More...Can the nucleotide content of a DNA sequence predict the sequence accessibility?

Sequence accessibility is an important factor affecting gene expression. Sequence accessibility or openness impacts the likelihood that a gene is transcribed and translated into a protein and performs functions and manifests traits. There are many potential factors that affect the accessibility of a gene. In this study, our hypothesis was that the content of nucleotides in a genetic sequence predicts its accessibility. Using a machine learning linear regression model, we studied the relationship between nucleotide content and accessibility.
Read More...Predicting asthma-related emergency department visits and hospitalizations with machine learning techniques

Seeking to investigate the effects of ambient pollutants on human respiratory health, here the authors used machine learning to examine asthma in Lost Angeles County, an area with substantial pollution. By using machine learning models and classification techniques, the authors identified that nitrogen dioxide and ozone levels were significantly correlated with asthma hospitalizations. Based on an identified seasonal surge in asthma hospitalizations, the authors suggest future directions to improve machine learning modeling to investigate these relationships.
Read More...Building a video classifier to improve the accuracy of depth-aware frame interpolation
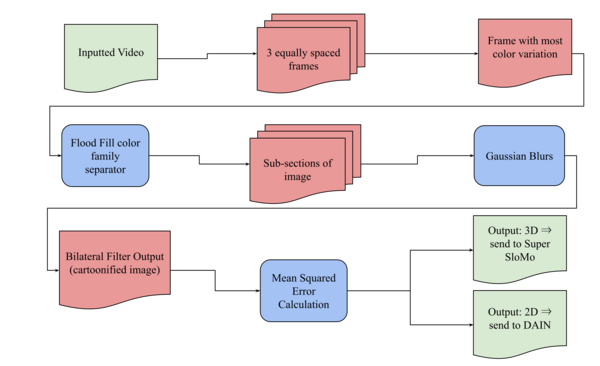
In this study, the authors share their work on improving the frame rate of videos to reduce data sent to users with both 2D and 3D footage. This work helps improve the experience for both types of footage!
Read More...Comparison of the ease of use and accuracy of two machine learning algorithms – forestry case study

Machine learning algorithms are becoming increasingly popular for data crunching across a vast area of scientific disciplines. Here, the authors compare two machine learning algorithms with respect to accuracy and user-friendliness and find that random forest algorithms outperform logistic regression when applied to the same dataset.
Read More...Transfer Learning for Small and Different Datasets: Fine-Tuning A Pre-Trained Model Affects Performance
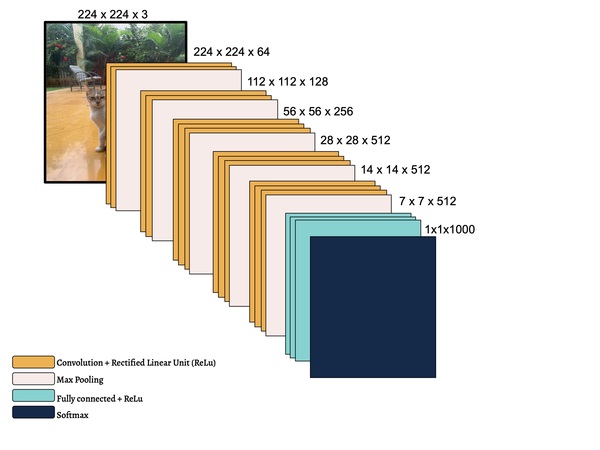
In this study, the authors seek to improve a machine learning algorithm used for image classification: identifying male and female images. In addition to fine-tuning the classification model, they investigate how accuracy is affected by their changes (an important task when developing and updating algorithms). To determine accuracy, a set of images is used to train the model and then a separate set of images is used for validation. They found that the validation accuracy was close to the training accuracy. This study contributes to the expanding areas of machine learning and its applications to image identification.
Read More...Using text embedding models as text classifiers with medical data

This article describes the classification of medical text data using vector databases and text embedding. Various large language models were used to generate this medical data for the classification task.
Read More...The precision of machine learning models at classifying autism spectrum disorder in adults
.png)
Autism spectrum disorder (ASD) is hard to correctly diagnose due to the very subjective nature of diagnosing it: behavior analysis. Due to this issue, we sought to find a machine learning-based method that diagnoses ASD without behavior analysis or helps reduce misdiagnosis.
Read More...Groundwater prediction using artificial intelligence: Case study for Texas aquifers
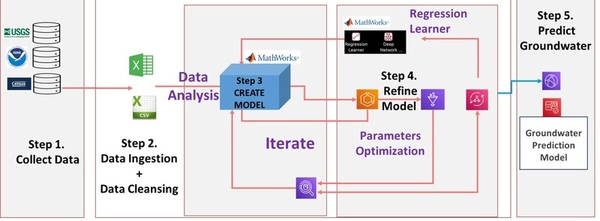
Here, in an effort to develop a model to predict future groundwater levels, the authors tested a tree-based automated artificial intelligence (AI) model against other methods. Through their analysis they found that groundwater levels in Texas aquifers are down significantly, and found that tree-based AI models most accurately predicted future levels.
Read More...The impact of genetic analysis on the early detection of colorectal cancer
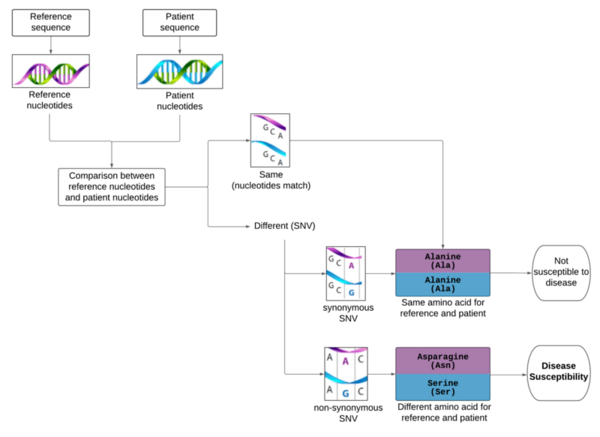
Although the 5-year survival rate for colorectal cancer is below 10%, it increases to greater than 90% if it is diagnosed early. We hypothesized from our research that analyzing non-synonymous single nucleotide variants (SNVs) in a patient's exome sequence would be an indicator for high genetic risk of developing colorectal cancer.
Read More...