
Studying cut-resistant socks for hockey players
Read More...A systematic study of cut-resistant socks for hockey players
Pressing filtration for extraction of cabbage dietary fiber and soluble components

Here the authors introduce pressing filtration as a novel, efficient, and low-energy method for extracting dietary fiber from cabbage, which successfully retains heat-sensitive nutrients and achieves a high fiber yield. The study demonstrates the scalability and economic viability of this technique for commercial use, highlighting that the resulting high-fiber cabbage powder can be incorporated into familiar foods like hamburger buns and beef patties without compromising taste or sensory quality.
Read More...Correlates of Sugar Consumption Among High School Students and Faculty

The availability, portion sizes, and consumption of highly palatable food has been linked adverse health outcomes. McBurnett and O’Donnell sought to assess the relationship between reward-based eating drive, consumption, cravings, and knowledge of the effects of sugary foods. In this study population, reward-based eating drive was related to both consumption and cravings. Further, for females, the knowledge of sugar’s effects was significantly and inversely associated with its consumption.
Read More...Improper storage of sunscreen might decrease effectiveness
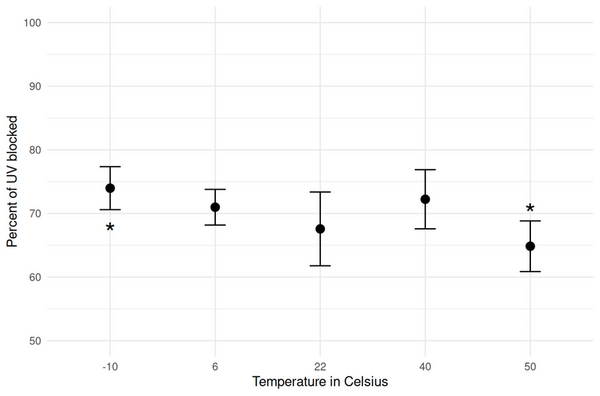
This study explored sunscreen storage temperature affects the efficacy of sunscreen to block UV light.
Read More...The correlation between bacteria and colorectal cancer
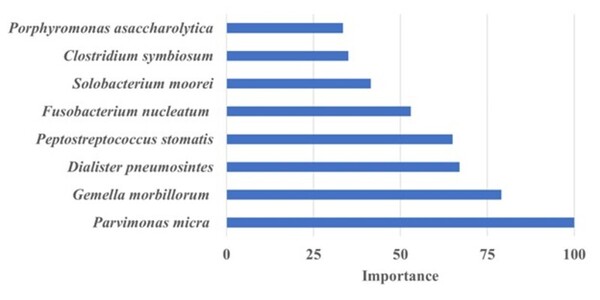
The authors looked at abundance of bacteria in stool samples from patients with colorectal cancer compared to controls. They found different bacteria that was more prevalent in patients with colorectal cancer as well as bacteria in control patients that may indicate a beneficial gut microbiome.
Read More...Extracellular vesicles derived from oxidatively stressed stromal cells promote cancer progression
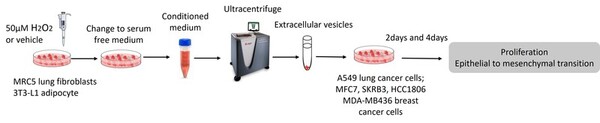
This paper hypothesized that the tumor microenvironment mediates cancer’s response to oxidative stress by delivering extracellular vesicles to cancer cells. Breast and lung cancer cells were treated with EVs, reavealing that EVs extracted from oxidatively stressed adipocytes increased the cell proliferation of breast cancer cells. These findings present a novel way that the TME influences cancer progression.
Read More...Protective effect of bromelain and pineapple extracts on UV-induced damage in human skin cells

In this study, the authors tested whether the compound bromelain extracted from pineapples could protect skin cells from UV damage.
Read More...Reducing levels of C-Reactive Protein: An eight-week, open-label clinical trial of three oral supplements

In this study, the effects of vitamin C, ginger, or curcumin supplements on C-reactive protein levels in healthy participants are determined in an eight-week open-label trial.
Read More...Colorism and the killing of unarmed African Americans by police

The purpose of this study was to investigate the relationship between colorism and police killings of unarmed African American suspects. The authors collected data from the Washington Post database, which reports unarmed African American victims from 2015–2021, and found that the victims who were killed by police were darker on average than a control population of African Americans that had not encountered the police.
Read More...Evaluating cinnamaldehyde as an antibacterial agent in a produce wash for leafy greens

Recognizing a growing demand for organic produce, the authors sought to investigate plant-based antibiotic solutions to meet growing consumer demand for safe produce and also meet microbial standards of the USDA. The authors investigated the use of cinnamaldehyde as an antibacterial again E. coli, finding that lettuce treated with cinnamaldehyde displayed significantly lower colony-forming units of E. coli when compared to lettuce treated with chlorine bleach.
Read More...