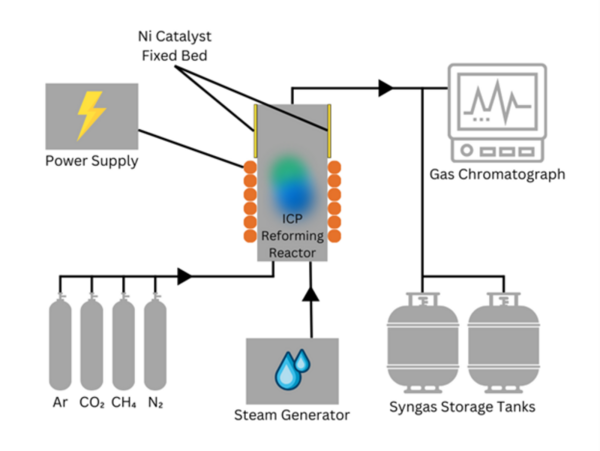
The escalating crisis of climate change, driven by the accumulation of greenhouse gases from human activities, demands urgent and innovative solutions to curb rising global temperatures. Plasma-based methane (CH4) and carbon dioxide (CO2) reforming offers a promising pathway for carbon capture and the sustainable production of hydrogen fuel and syngas components. To advance this technology, particularly in terms of energy efficiency and selectivity, it is essential to enhance the conversion efficiencies of CO2 and CH4.
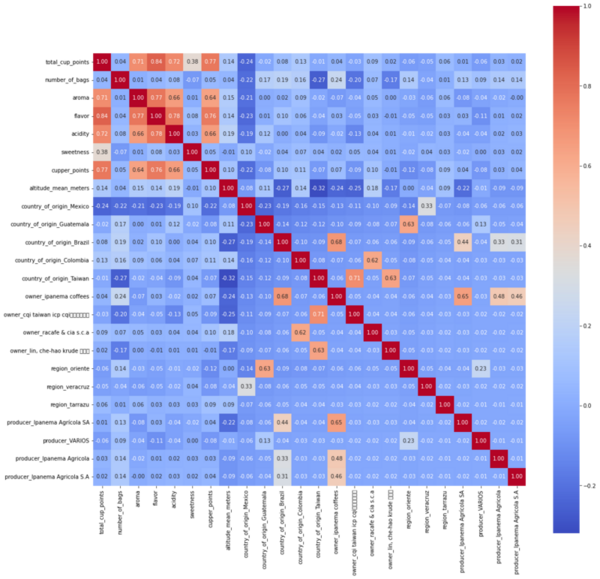
This study explores the factors that influence coffee quality ratings using data from the Coffee Quality Institute. Through a regression model based on gradient descent, the authors aimed to predict coffee ratings (total cup points) and hypothesized that sweetness and the coffee producer would be the most influential factors.
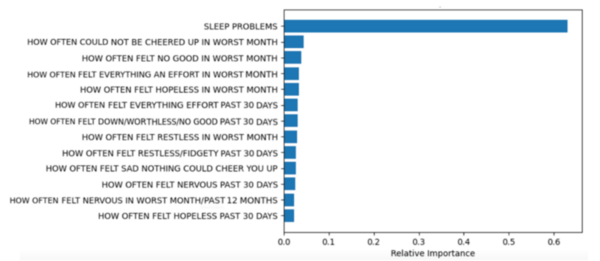
Sadly, around 800,000 people die by suicide worldwide each year. Dong and Pearce analyze health survey data to identify associations between suicidal ideation and relevant variables, such as sleep quality, hopelessness, and anxious behavior.
A bottleneck in deleting algal blooms is that current data section is manual and is reactionary to an existing algal bloom. These authors made a custom-designed Seek and Destroy Algal Mitigation System (SDAMS) that detects harmful algal blooms at earlier time points with astonishing accuracy, and can instantaneously suppress the pre-bloom algal population.
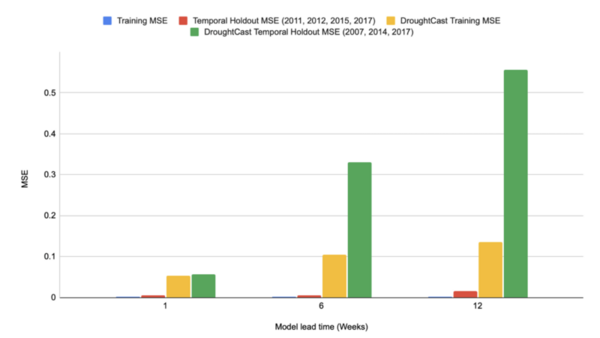
Droughts kill over 45,000 people yearly and affect the livelihoods of 55 million others worldwide, with climate change likely to worsen these effects. However, unlike other natural disasters (hurricanes, etc.), there is no early detection system that can predict droughts far enough in advance to be useful. Bora, Caulkins, and Joycutty tackle this issue by creating a drought prediction model.
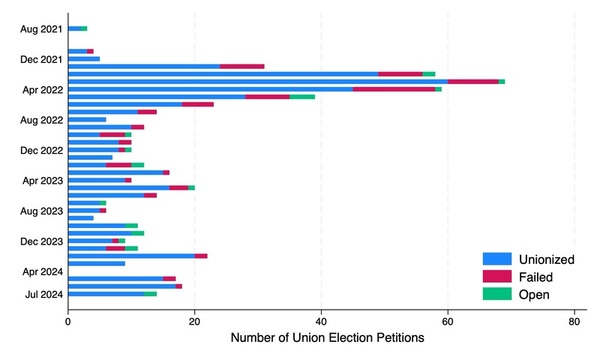
The authors looked at unionization petitions from Starbucks workers between August 2021 and July 2024 to determine what factors influence votes for or against unionization.
Given an association between nicotine addiction and gene expression, we hypothesized that expression of genes commonly associated with smoking status would have variable expression between smokers and non-smokers. To test whether gene expression varies between smokers and non-smokers, we analyzed two publicly-available datasets that profiled RNA gene expression from brain (nucleus accumbens) and lung tissue taken from patients identified as smokers or non-smokers. We discovered statistically significant differences in expression of dozens of genes between smokers and non-smokers. To test whether gene expression can be used to predict whether a patient is a smoker or non-smoker, we used gene expression as the training data for a logistic regression or random forest classification model. The random forest classifier trained on lung tissue data showed the most robust results, with area under curve (AUC) values consistently between 0.82 and 0.93. Both models trained on nucleus accumbens data had poorer performance, with AUC values consistently between 0.65 and 0.7 when using random forest. These results suggest gene expression can be used to predict smoking status using traditional machine learning models. Additionally, based on our random forest model, we proposed KCNJ3 and TXLNGY as two candidate markers of smoking status. These findings, coupled with other genes identified in this study, present promising avenues for advancing applications related to the genetic foundation of smoking-related characteristics.