This study hypothesized that a machine learning model could accurately predict the severity of California wildfires and determine the most influential meteorological factors. It utilized a custom dataset with information from the World Weather Online API and a Kaggle dataset of wildfires in California from 2013-2020. The developed algorithms classified fires into seven categories with promising accuracy (around 55 percent). They found that higher temperatures, lower humidity, lower dew point, higher wind gusts, and higher wind speeds are the most significant contributors to the spread of a wildfire. This tool could vastly improve the efficiency and preparedness of firefighters as they deal with wildfires.
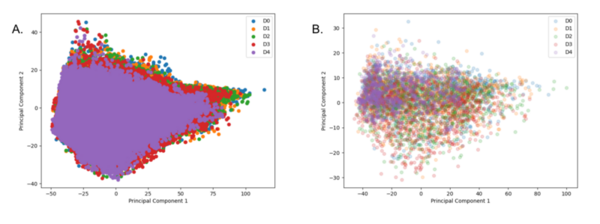
Here, recognizing the difficulty associated with tracking the progression of dementia, the authors used machine learning models to predict between the presence of cognitive normalcy, mild cognitive impairment, and Alzheimer's Disease, based on blood DNA methylation levels, sex, and age. With four machine learning models and two dataset dimensionality reduction methods they achieved an accuracy of 53.33%.
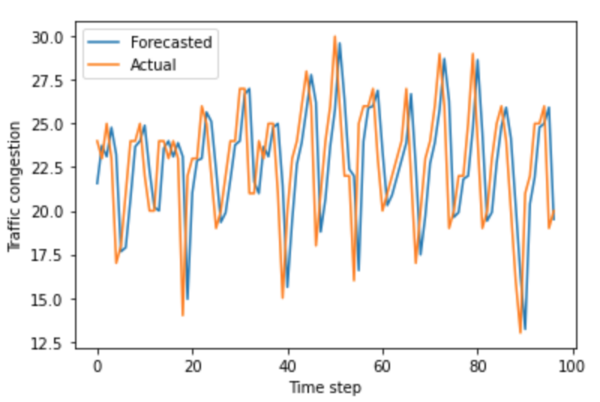
In this paper, we measured the privacy budgets and utilities of different differentially private mechanisms combined with different machine learning models that forecast traffic congestion at future timestamps. We expected the ANNs combined with the Staircase mechanism to perform the best with every value in the privacy budget range, especially with the medium high values of the privacy budget. In this study, we used the Autoregressive Integrated Moving Average (ARIMA) and neural network models to forecast and then added differentially private Laplacian, Gaussian, and Staircase noise to our datasets. We tested two real traffic congestion datasets, experimented with the different models, and examined their utility for different privacy budgets. We found that a favorable combination for this application was neural networks with the Staircase mechanism. Our findings identify the optimal models when dealing with tricky time series forecasting and can be used in non-traffic applications like disease tracking and population growth.
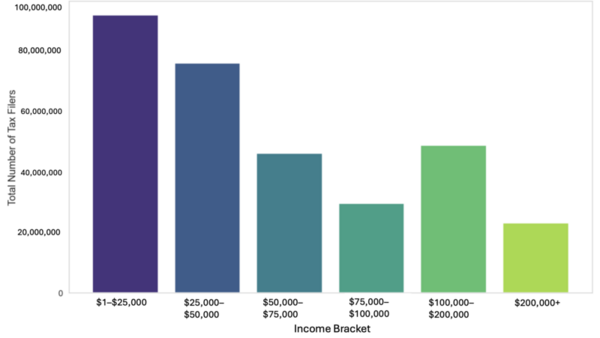
Tax incentives for sustainable technology are a key part of the push for a greener future. However, these incentives may not reach all income strata equally. Using a machine learning approach, this study analyzed the distributional effects of residential energy tax credits across different income levels in the United States.
Depression affects millions globally, yet identifying symptoms remains challenging. This study explored detecting depression-related patterns in social media texts using natural language processing and machine learning algorithms, including decision trees and random forests. Our findings suggest that analyzing online text activity can serve as a viable method for screening mental disorders, potentially improving diagnosis accuracy by incorporating both physical and psychological indicators.
The mountain chain of the Western Ghats on the Indian peninsula, a UNESCO World Heritage site, is home to about 200 frog species, 89 of which are endemic. Distinctive to each frog species, their vocalizations can be used for species recognition. Manually surveying frogs at night during the rain in elephant and big cat forests is difficult, so being able to autonomously record ambient soundscapes and identify species is essential. An effective machine learning (ML) species classifier requires substantial training data from this area. The goal of this study was to assess data augmentation techniques on a dataset of frog vocalizations from this region, which has a minimal number of audio recordings per species. Consequently, enhancing an ML model’s performance with limited data is necessary. We analyzed the effects of four data augmentation techniques (Time Shifting, Noise Injection, Spectral Augmentation, and Test-Time Augmentation) individually and their combined effect on the frog vocalization data and the public environmental sounds dataset (ESC-50). The effect of combined data augmentation techniques improved the model's relative accuracy as the size of the dataset decreased. The combination of all four techniques improved the ML model’s classification accuracy on the frog calls dataset by 94%. This study established a data augmentation approach to maximize the classification accuracy with sparse data of frog call recordings, thereby creating a possibility to build a real-world automated field frog species identifier system. Such a system can significantly help in the conservation of frog species in this vital biodiversity hotspot.
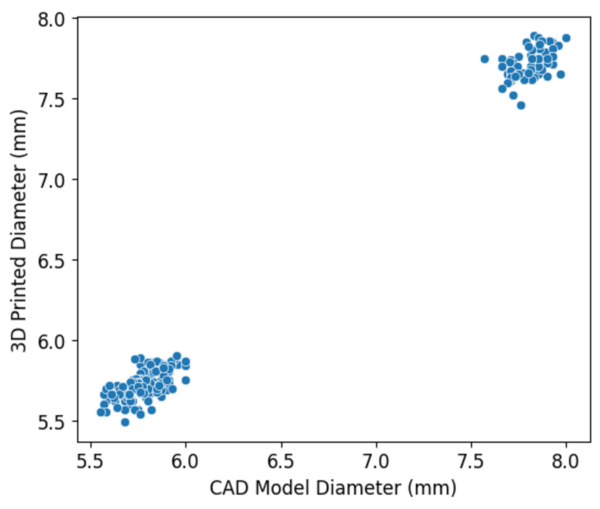
This study explores how to predict and minimize distortion in 3D printed parts, particularly when using affordable PLA filament. The researchers developed a model using a gradient boosting regressor trained on 3D printing data, aiming to predict the necessary CAD dimensions to counteract print distortion.
Droughts have a wide range of effects, from ecosystems failing and crops dying, to increased illness and decreased water quality. Drought prediction is important because it can help communities, businesses, and governments plan and prepare for these detrimental effects. This study predicts drought conditions by using predictable weather patterns in machine learning models.