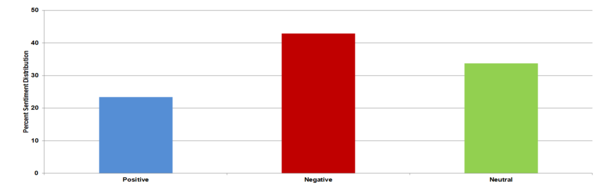
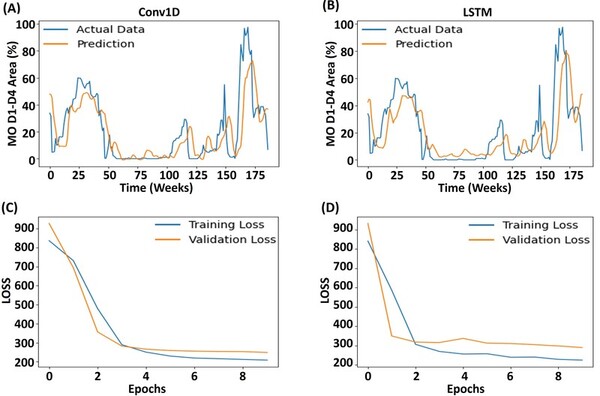
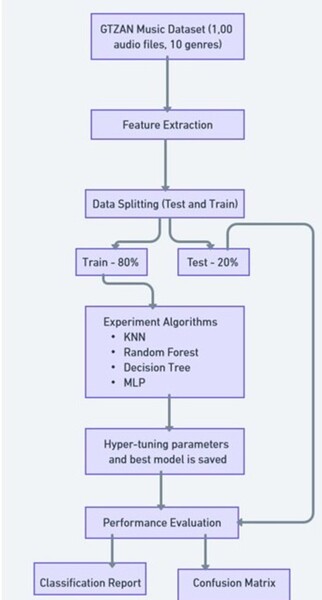
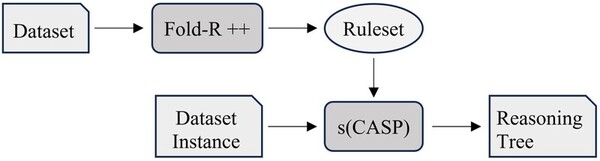
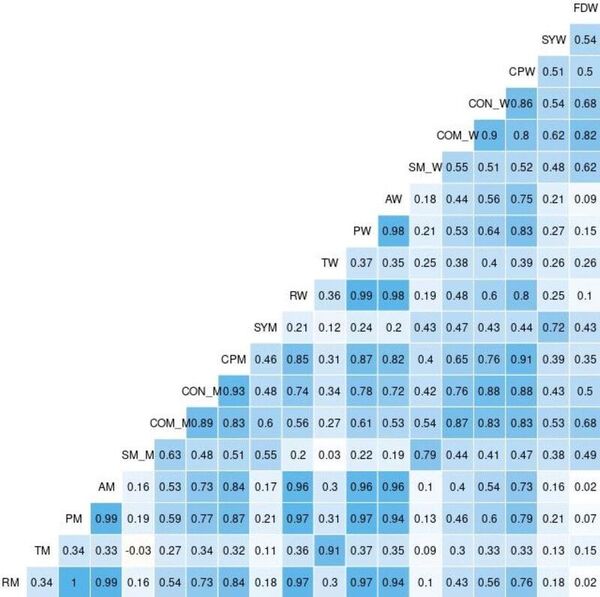
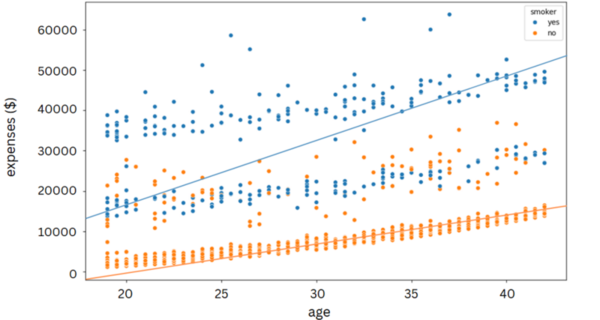
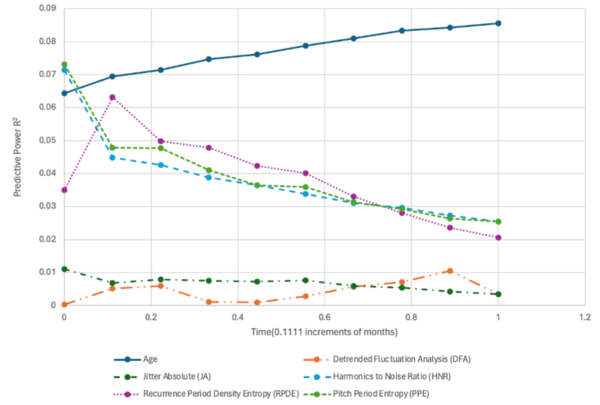
This study contributes to our understanding of how urban energy systems respond to climate variability and inform strategies for enhancing power grid resilience. The findings can help inform urban planners and infrastructure developers by identifying the factors that make regions within a power grid more vulnerable.
Read More...