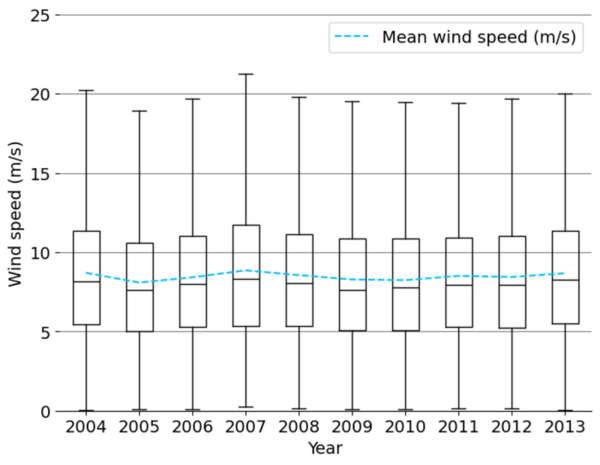
The authors looked at the feasibility to predict wind speeds that will have less reliance on using historical data.
Read More...Evaluating the effectiveness of synthetic training data for day-ahead wind speed prediction in the Great Lakes
The authors looked at the feasibility to predict wind speeds that will have less reliance on using historical data.
Read More...The impact of conceptual versus memorization-based teaching methods on student performance

The authors looked at how students performed on standardized tests when they were taught material via memorization vs. conceptual based approaches.
Read More...Evaluating the feasibility of SMILES-based autoencoders for drug discovery
The authors investigate the ability of machine learning models to developing new drug-like molecules by learning desired chemical properties versus simply generating molecules that similar to those in the training set.
Read More...Transfer learning and data augmentation in osteosarcoma cancer detection
Osteosarcoma is a type of bone cancer that affects young adults and children. Early diagnosis of osteosarcoma is crucial to successful treatment. The current methods of diagnosis, which include imaging tests and biopsy, are time consuming and prone to human error. Hence, we used deep learning to extract patterns and detect osteosarcoma from histological images. We hypothesized that the combination of two different technologies (transfer learning and data augmentation) would improve the efficacy of osteosarcoma detection in histological images. The dataset used for the study consisted of histological images for osteosarcoma and was quite imbalanced as it contained very few images with tumors. Since transfer learning uses existing knowledge for the purpose of classification and detection, we hypothesized it would be proficient on such an imbalanced dataset. To further improve our learning, we used data augmentation to include variations in the dataset. We further evaluated the efficacy of different convolutional neural network models on this task. We obtained an accuracy of 91.18% using the transfer learning model MobileNetV2 as the base model with various geometric transformations, outperforming the state-of-the-art convolutional neural network based approach.
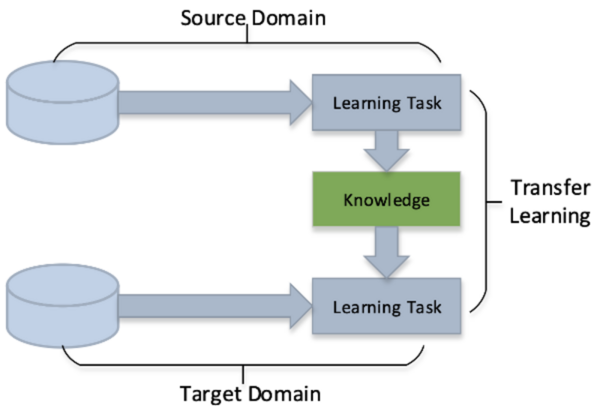
Read More...Transfer Learning for Small and Different Datasets: Fine-Tuning A Pre-Trained Model Affects Performance
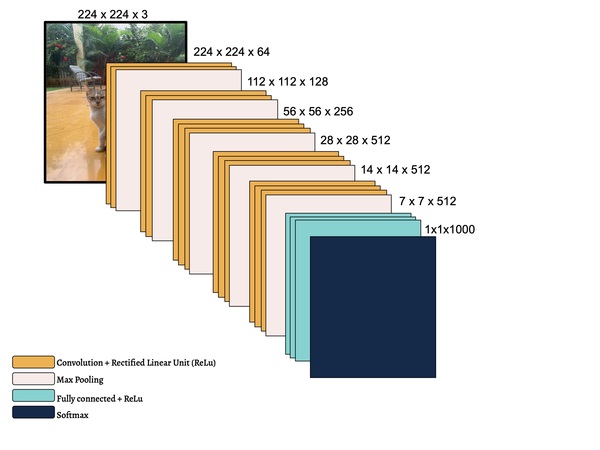
In this study, the authors seek to improve a machine learning algorithm used for image classification: identifying male and female images. In addition to fine-tuning the classification model, they investigate how accuracy is affected by their changes (an important task when developing and updating algorithms). To determine accuracy, a set of images is used to train the model and then a separate set of images is used for validation. They found that the validation accuracy was close to the training accuracy. This study contributes to the expanding areas of machine learning and its applications to image identification.
Read More...Using advanced machine learning and voice analysis features for Parkinson’s disease progression prediction
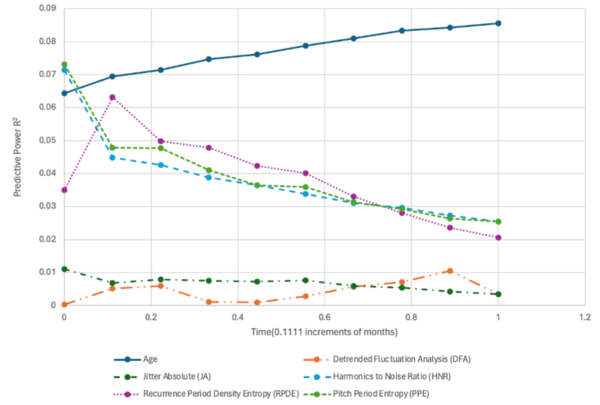
The authors looked at the ability to use audio clips to analyze the progression of Parkinson's disease.
Read More...Modeling and optimization of epidemiological control policies through reinforcement learning
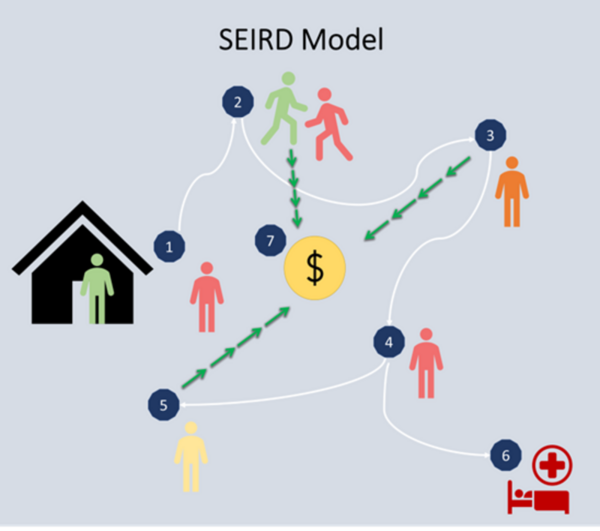
Pandemics involve the high transmission of a disease that impacts global and local health and economic patterns. Epidemiological models help propose pandemic control strategies based on non-pharmaceutical interventions such as social distancing, curfews, and lockdowns, reducing the economic impact of these restrictions. In this research, we utilized an epidemiological Susceptible, Exposed, Infected, Recovered, Deceased (SEIRD) model – a compartmental model for virtually simulating a pandemic day by day.
Read More...Spelling Bee: A Study on the Motivation and Learning Strategies Among Elementary and Junior-High Student Competitors
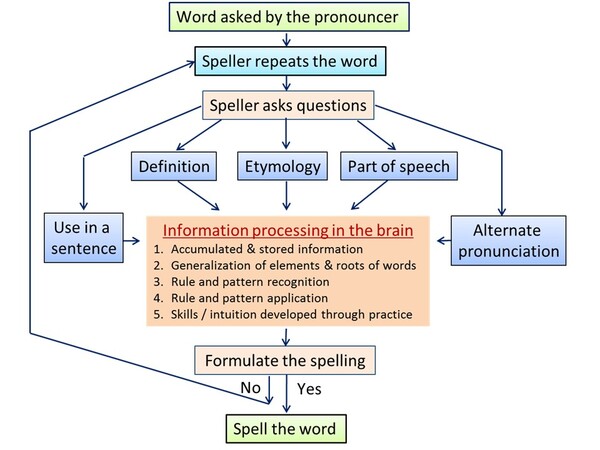
This article investigates the study methodologies, learning strategies, and motives of spelling bee participants. The authors identify several important educational implications of this work.
Read More...Risk assessment modeling for childhood stunting using automated machine learning and demographic analysis
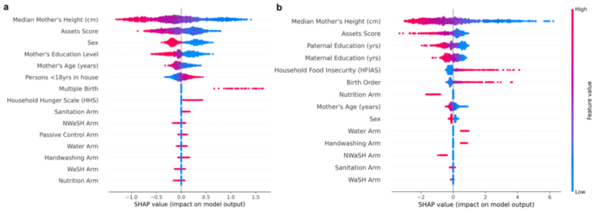
Over the last few decades, childhood stunting has persisted as a major global challenge. This study hypothesized that TPTO (Tree-based Pipeline Optimization Tool), an AutoML (automated machine learning) tool, would outperform all pre-existing machine learning models and reveal the positive impact of economic prosperity, strong familial traits, and resource attainability on reducing stunting risk. Feature correlation plots revealed that maternal height, wealth indicators, and parental education were universally important features for determining stunting outcomes approximately two years after birth. These results help inform future research by highlighting how demographic, familial, and socio-economic conditions influence stunting and providing medical professionals with a deployable risk assessment tool for predicting childhood stunting.
Read More...A machine learning approach for abstraction and reasoning problems without large amounts of data

While remarkable in its ability to mirror human cognition, machine learning and its associated algorithms often require extensive data to prove effective in completing tasks. However, data is not always plentiful, with unpredictable events occurring throughout our daily lives that require flexibility by artificial intelligence utilized in technology such as personal assistants and self-driving vehicles. Driven by the need for AI to complete tasks without extensive training, the researchers in this article use fluid intelligence assessments to develop an algorithm capable of generalization and abstraction. By forgoing prioritization on skill-based training, this article demonstrates the potential of focusing on a more generalized cognitive ability for artificial intelligence, proving more flexible and thus human-like in solving unique tasks than skill-focused algorithms.
Read More...