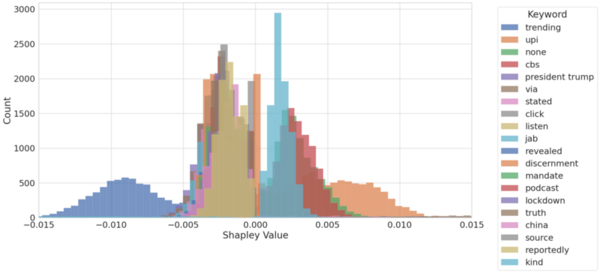
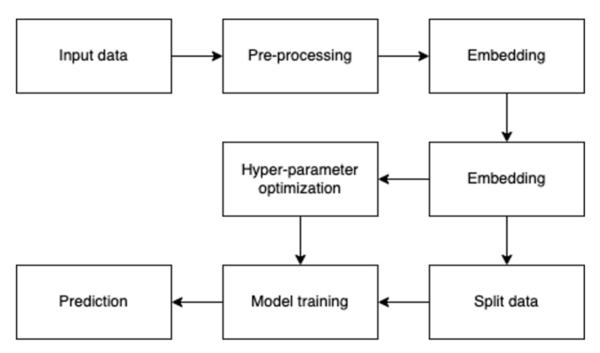
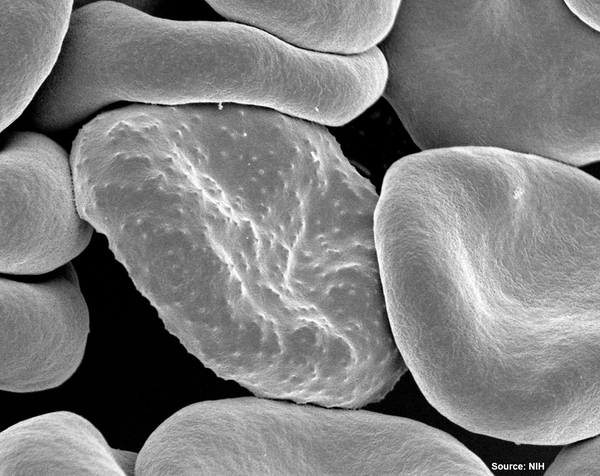
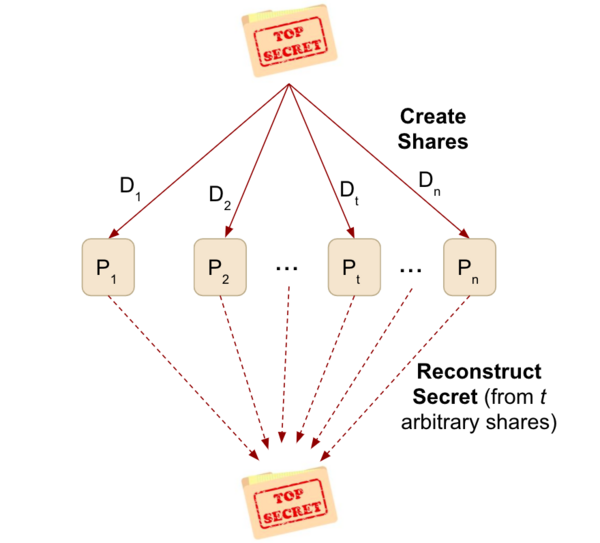
The authors looked at the ability of machine learning algorithms to interpret language given their increasing use in moderating content on social media. Using an explainable model they were able to achieve 81% accuracy in detecting fake vs. real news based on language of posts alone.
While remarkable in its ability to mirror human cognition, machine learning and its associated algorithms often require extensive data to prove effective in completing tasks. However, data is not always plentiful, with unpredictable events occurring throughout our daily lives that require flexibility by artificial intelligence utilized in technology such as personal assistants and self-driving vehicles. Driven by the need for AI to complete tasks without extensive training, the researchers in this article use fluid intelligence assessments to develop an algorithm capable of generalization and abstraction. By forgoing prioritization on skill-based training, this article demonstrates the potential of focusing on a more generalized cognitive ability for artificial intelligence, proving more flexible and thus human-like in solving unique tasks than skill-focused algorithms.
Depression affects millions globally, yet identifying symptoms remains challenging. This study explored detecting depression-related patterns in social media texts using natural language processing and machine learning algorithms, including decision trees and random forests. Our findings suggest that analyzing online text activity can serve as a viable method for screening mental disorders, potentially improving diagnosis accuracy by incorporating both physical and psychological indicators.
This study hypothesized that a machine learning model could accurately predict the severity of California wildfires and determine the most influential meteorological factors. It utilized a custom dataset with information from the World Weather Online API and a Kaggle dataset of wildfires in California from 2013-2020. The developed algorithms classified fires into seven categories with promising accuracy (around 55 percent). They found that higher temperatures, lower humidity, lower dew point, higher wind gusts, and higher wind speeds are the most significant contributors to the spread of a wildfire. This tool could vastly improve the efficiency and preparedness of firefighters as they deal with wildfires.
The diagnosis of malaria remains one of the major hurdles to eradicating the disease, especially among poorer populations. Here, the authors use machine learning to improve the accuracy of deep learning algorithms that automate the diagnosis of malaria using images of blood smears from patients, which could make diagnosis easier and faster for many.
Auto-Regressive Integrated Moving Average (ARIMA) models are known for their influence and application on time series data. This statistical analysis model uses time series data to depict future trends or values: a key contributor to crime mapping algorithms. However, the models may not function to their true potential when analyzing data with many different patterns. In order to determine the potential of ARIMA models, our research will test the model on irregularities in the data. Our team hypothesizes that the ARIMA model will be able to adapt to the different irregularities in the data that do not correspond to a certain trend or pattern. Using crime theft data and an ARIMA model, we determined the results of the ARIMA model’s forecast and how the accuracy differed on different days with irregularities in crime.
In this study, the authors develop an architecture to implement in a cloud-based database used by law firms to ensure confidentiality, availability, and integrity of attorney documents while maintaining greater efficiency than traditional encryption algorithms. They assessed whether the architecture satisfies necessary criteria and tested the overall file sizes the architecture could process. The authors found that their system was able to handle larger file sizes and fit engineering criteria. This study presents a valuable new tool that can be used to ensure law firms have adequate security as they shift to using cloud-based storage systems for their files.
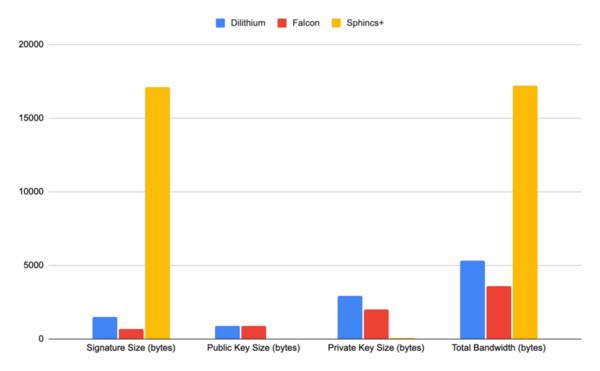
The advent of quantum computing will pose a substantial threat to the security of classical cryptographic methods, which could become vulnerable to quantum-based attacks. In response to this impending challenge, the field of post-quantum cryptography has emerged, aiming to develop algorithms that can withstand the computational power of quantum computers. This study addressed the pressing concern of classical cryptographic methods becoming vulnerable to quantum-based attacks due to the rise of quantum computing. The emergence of post-quantum cryptography has led to the development of new resistant algorithms. Our research focused on four quantum-resistant algorithms endorsed by America’s National Institute of Standards and Technology (NIST) in 2022: CRYSTALS-Kyber, CRYSTALS-Dilithium, FALCON, and SPHINCS+. This study evaluated the security, performance, and comparative attributes of the four algorithms, considering factors such as key size, encryption/decryption speed, and complexity. Comparative analyses against each other and existing quantum-resistant algorithms provided insights into the strengths and weaknesses of each program. This research explored potential applications and future directions in the realm of quantum-resistant cryptography. Our findings concluded that the NIST algorithms were substantially more effective and efficient compared to classical cryptographic algorithms. Ultimately, this work underscored the need to adapt cryptographic techniques in the face of advancing quantum computing capabilities, offering valuable insights for researchers and practitioners in the field. Implementing NIST-endorsed quantum-resistant algorithms substantially reduced the vulnerability of cryptographic systems to quantum-based attacks compared to classical cryptographic methods.
Image credit: Chunduri, Srinivas and McMahan, 2024.
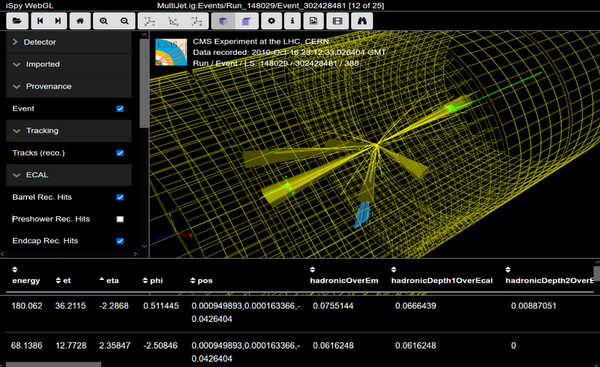
Collisions of heavy ions, such as muons result in jets and noise. In high-energy particle physics, researchers use jets as crucial event-shaped observable objects to determine the properties of a collision. However, many ionic collisions result in large amounts of energy lost as noise, thus reducing the efficiency of collisions with heavy ions. The purpose of our study is to analyze the relationships between properties of muons in a dimuon collision to optimize conditions of dimuon collisions and minimize the noise lost. We used principles of Newtonian mechanics at the particle level, allowing us to further analyze different models. We used simple Python algorithms as well as linear regression models with tools such as sci-kit Learn, NumPy, and Pandas to help analyze our results. We hypothesized that since the invariant mass, the energy, and the resultant momentum vector are correlated with noise, if we constrain these inputs optimally, there will be scenarios in which the noise of the heavy-ion collision is minimized.
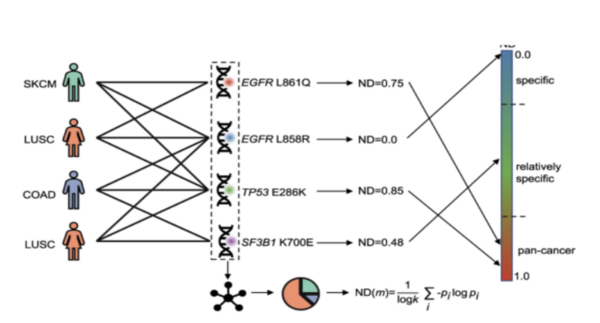
Breast cancer is the most common cancer in women, with approximately 300,000 diagnosed with breast cancer in 2023. It ranks second in cancer-related deaths for women, after lung cancer with nearly 50,000 deaths. Scientists have identified important genetic mutations in genes like BRCA1 and BRCA2 that lead to the development of breast cancer, but previous studies were limited as they focused on specific populations. To overcome limitations, diverse populations and powerful statistical methods like genome-wide association studies and whole-genome sequencing are needed. Explainable artificial intelligence (XAI) can be used in oncology and breast cancer research to overcome these limitations of specificity as it can analyze datasets of diagnosed patients by providing interpretable explanations for identified patterns and predictions. This project aims to achieve technological and medicinal goals by using advanced algorithms to identify breast cancer subtypes for faster diagnoses. Multiple methods were utilized to develop an efficient algorithm. We hypothesized that an XAI approach would be best as it can assign scores to genes, specifically with a 90% success rate. To test that, we ran multiple trials utilizing XAI methods through the identification of class-specific and patient-specific key genes. We found that the study demonstrated a pipeline that combines multiple XAI techniques to identify potential biomarker genes for breast cancer with a 95% success rate.