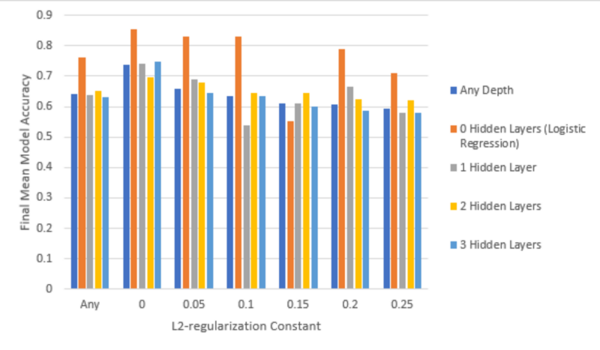
Sequence accessibility is an important factor affecting gene expression. Sequence accessibility or openness impacts the likelihood that a gene is transcribed and translated into a protein and performs functions and manifests traits. There are many potential factors that affect the accessibility of a gene. In this study, our hypothesis was that the content of nucleotides in a genetic sequence predicts its accessibility. Using a machine learning linear regression model, we studied the relationship between nucleotide content and accessibility.
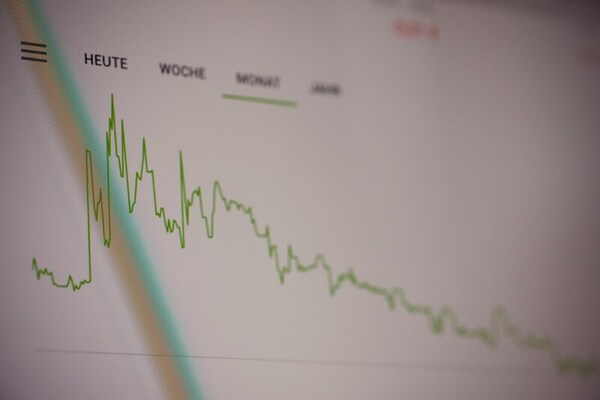
Algorithmic trading has been increasingly used by Americans. In this work, we tested whether including the opening, closing, and highest prices in three supervised learning models affected their performance. Indeed, we found that including all three prices decreased the error of the prediction significantly.
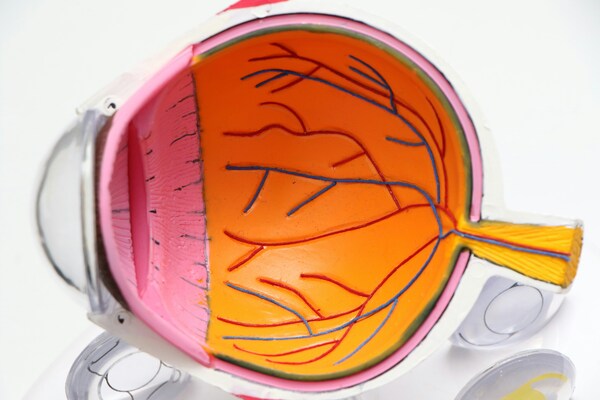
This study examined whether eye color affects photophobia and vision in elementary school students and staff, finding no significant relationship between eye color, light sensitivity, or visual acuity. However, photophobia was common across age groups, highlighting the need for greater awareness of light sensitivity in learning environments.
Although there has been great progress in the field of Natural language processing (NLP) over the last few years, particularly with the development of attention-based models, less research has contributed towards modeling keystroke log data. State of the art methods handle textual data directly and while this has produced excellent results, the time complexity and resource usage are quite high for such methods. Additionally, these methods fail to incorporate the actual writing process when assessing text and instead solely focus on the content. Therefore, we proposed a framework for modeling textual data using keystroke-based features. Such methods pay attention to how a document or response was written, rather than the final text that was produced. These features are vastly different from the kind of features extracted from raw text but reveal information that is otherwise hidden. We hypothesized that pairing efficient machine learning techniques with keystroke log information should produce results comparable to transformer techniques, models which pay more or less attention to the different components of a text sequence in a far quicker time. Transformer-based methods dominate the field of NLP currently due to the strong understanding they display of natural language. We showed that models trained on keystroke log data are capable of effectively evaluating the quality of writing and do it in a significantly shorter amount of time compared to traditional methods. This is significant as it provides a necessary fast and cheap alternative to increasingly larger and slower LLMs.
Here recognizing the growing amount of plastic waste in the oceans, the authors sought to develop and test laser imaging for the identification of waste in water. They found that while possible, limitations such as increasing depth and water turbidity result in increasing blurriness in laser images. While their image processing methods were somewhat insufficient they identified recent methods to use deep learning-based techniques as a potential avenue to viability for this method.
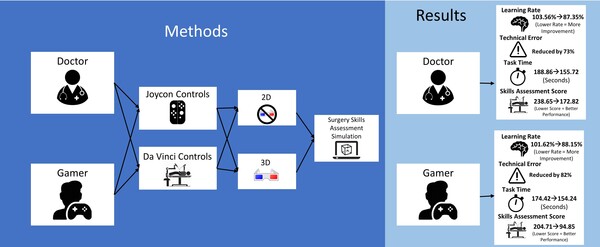
Complications of robotic-assisted surgery are on the rise, partly due to surgeons not receiving proper training. Al-Akash and Al-Akash hypothesized Nintendo JoyCon controls would improve surgical performance compared to the FDA-approved Da Vinci Surgical System with two user groups (doctor and gamer). Their results show that implementing a Nintendo JoyCon control system is associated with improved surgical performance and learning rate compared to the Da Vinci Surgical System.
Given an association between nicotine addiction and gene expression, we hypothesized that expression of genes commonly associated with smoking status would have variable expression between smokers and non-smokers. To test whether gene expression varies between smokers and non-smokers, we analyzed two publicly-available datasets that profiled RNA gene expression from brain (nucleus accumbens) and lung tissue taken from patients identified as smokers or non-smokers. We discovered statistically significant differences in expression of dozens of genes between smokers and non-smokers. To test whether gene expression can be used to predict whether a patient is a smoker or non-smoker, we used gene expression as the training data for a logistic regression or random forest classification model. The random forest classifier trained on lung tissue data showed the most robust results, with area under curve (AUC) values consistently between 0.82 and 0.93. Both models trained on nucleus accumbens data had poorer performance, with AUC values consistently between 0.65 and 0.7 when using random forest. These results suggest gene expression can be used to predict smoking status using traditional machine learning models. Additionally, based on our random forest model, we proposed KCNJ3 and TXLNGY as two candidate markers of smoking status. These findings, coupled with other genes identified in this study, present promising avenues for advancing applications related to the genetic foundation of smoking-related characteristics.
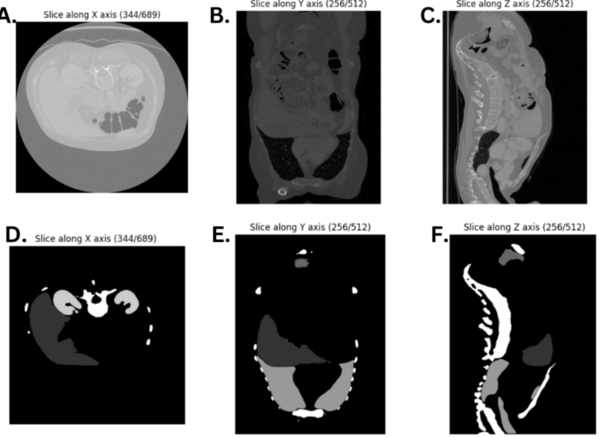
The authors looked at different models of semantic segmentation to determine which may be best used in the future for segmentation of CT scans to help diagnose certain conditions.
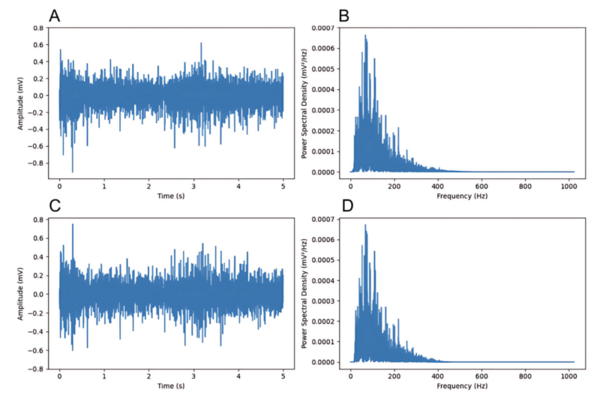
This manuscript evaluates peak detection algorithms for feature extraction in EMG-based hand gesture recognition using a random forest classifier. The study demonstrates that wavelet-based peak detection features achieve the highest classification accuracy (96.5%), outperforming other methods. The results highlight the potential of peak features to improve EMG-based prosthetic control systems.