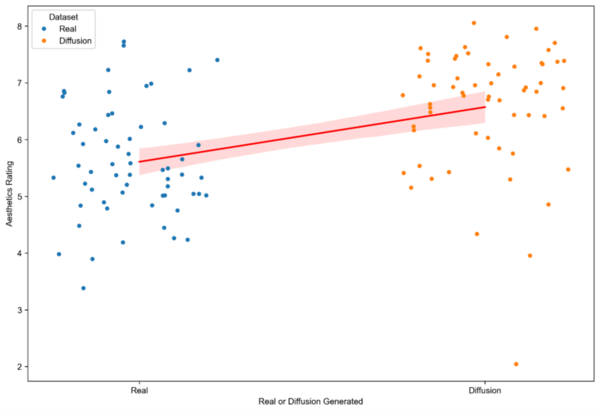
The authors develop a method for detecting fake AI-generated images from real images.
Read More...SpottingDiffusion: Using transfer learning to detect Latent Diffusion Model-synthesized images
Pruning replay buffer for efficient training of deep reinforcement learning

Reinforcement learning (RL) is a form of machine learning that can be harnessed to develop artificial intelligence by exposing the intelligence to multiple generations of data. The study demonstrates how reply buffer reward mechanics can inform the creation of new pruning methods to improve RL efficiency.
Read More...Prediction of molecular energy using Coulomb matrix and Graph Neural Network
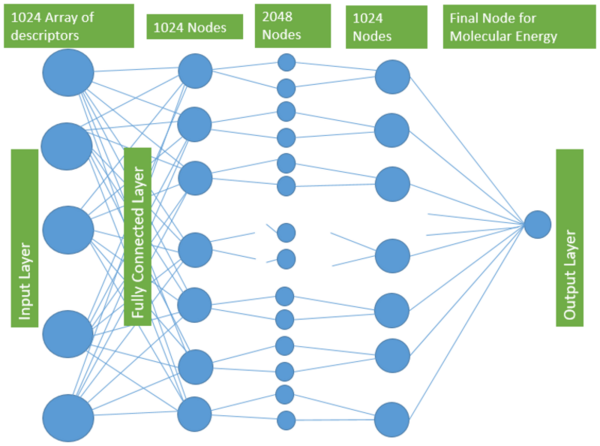
With molecular energy being an integral element to the study of molecules and molecular interactions, computational methods to determine molecular energy are used for the preservation of time and resources. However, these computational methods have high demand for computer resources, limiting their widespread feasibility. The authors of this study employed machine learning to address this disadvantage, utilizing neural networks trained on different representations of molecules to predict molecular properties without the requirement of computationally-intensive processing. In their findings, the authors determined the Feedforward Neural Network, trained by two separate models, as capable of predicting molecular energy with limited prediction error.
Read More...Predicting college retention rates from Google Street View images of campuses
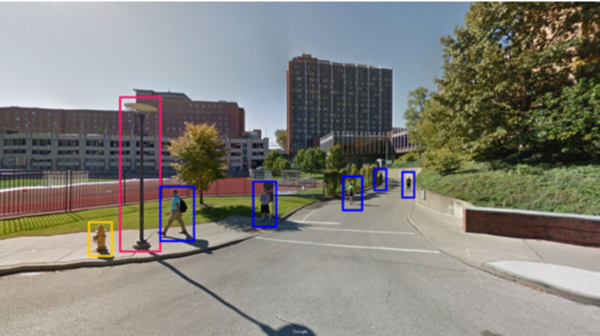
Every year, around 40% of undergraduate students in the United States discontinue their studies, resulting in a loss of valuable education for students and a loss of money for colleges. Even so, colleges across the nation struggle to discover the underlying causes of these high dropout rates. In this paper, the authors discuss the use of machine learning to find correlations between the built environment factors and the retention rates of colleges. They hypothesized that one way for colleges to improve their retention rates could be to improve the physical characteristics of their campus to be more pleasing. The authors used image classification techniques to look at images of colleges and correlate certain features like colors, cars, and people to higher or lower retention rates. With three possible options of high, medium, and low retention rates, the probability that their models reached the right conclusion if they simply chose randomly was 33%. After finding that this 33%, or 0.33 mark, always fell outside of the 99% confidence intervals built around their models’ accuracies, the authors concluded that their machine learning techniques can be used to find correlations between certain environmental factors and retention rates.
Read More...Prediction of diabetes using supervised classification
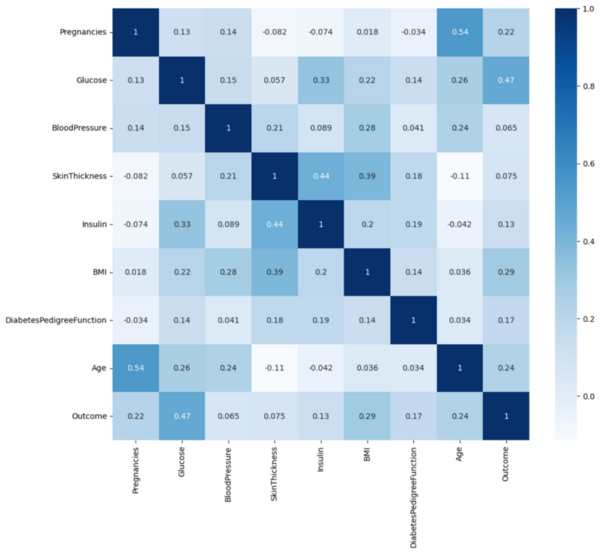
The authors develop and test a machine learning algorithm for predicting diabetes diagnoses.
Read More...Predicting the Instance of Breast Cancer within Patients using a Convolutional Neural Network
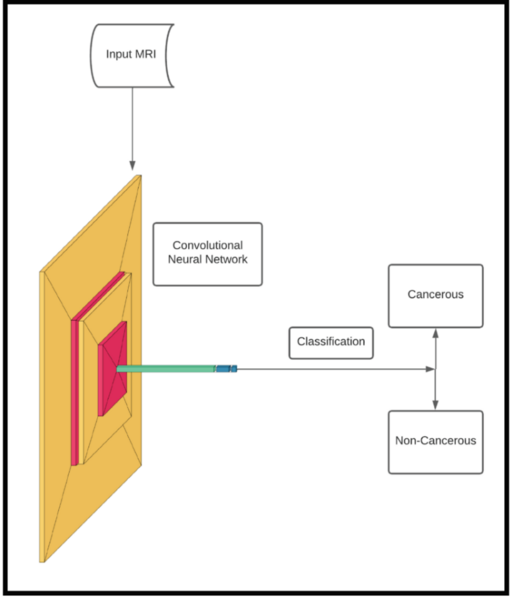
Using a convolution neural network, these authors show machine learning can clinically diagnose breast cancer with high accuracy.
Read More...SmartZoo: A Deep Learning Framework for an IoT Platform in Animal Care
Zoos offer educational and scientific advantages but face high maintenance costs and challenges in animal care due to diverse species' habits. Challenges include tracking animals, detecting illnesses, and creating suitable habitats. We developed a deep learning framework called SmartZoo to address these issues and enable efficient animal monitoring, condition alerts, and data aggregation. We discovered that the data generated by our model is closer to real data than random data, and we were able to demonstrate that the model excels at generating data that resembles real-world data.
Read More...Using broad health-related survey questions to predict the presence of coronary heart disease
Coronary heart disease (CHD) is the leading cause of death in the U.S., responsible for nearly 700,000 deaths in 2021, and is marked by artery clogging that can lead to heart attacks. Traditional prediction methods require expensive clinical tests, but a new study explores using machine learning on demographic, clinical, and behavioral survey data to predict CHD.
Read More...Identifying shark species using an AlexNet CNN model
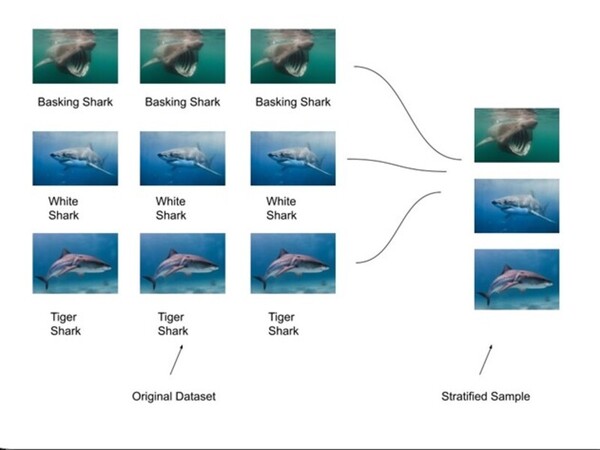
The challenge of accurately identifying shark species is crucial for biodiversity monitoring but is often hindered by time-consuming and labor-intensive manual methods. To address this, SharkNet, a CNN model based on AlexNet, achieved 93% accuracy in classifying shark species using a limited dataset of 1,400 images across 14 species. SharkNet offers a more efficient and reliable solution for marine biologists and conservationists in species identification and environmental monitoring.
Read More...The effects of image manipulation on classification of cervical spondylosis X-ray images using deep learning