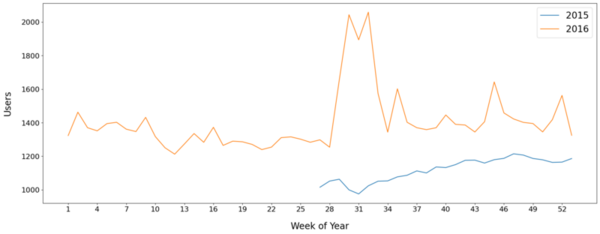
The authors looked at ways to provide better forecasting on website traffic. They found that deep learning models performed better than statistical models.
Read More...Deep sequential models versus statistical models for web traffic forecasting
The authors looked at ways to provide better forecasting on website traffic. They found that deep learning models performed better than statistical models.
Read More...Gradient boosting with temporal feature extraction for modeling keystroke log data
Although there has been great progress in the field of Natural language processing (NLP) over the last few years, particularly with the development of attention-based models, less research has contributed towards modeling keystroke log data. State of the art methods handle textual data directly and while this has produced excellent results, the time complexity and resource usage are quite high for such methods. Additionally, these methods fail to incorporate the actual writing process when assessing text and instead solely focus on the content. Therefore, we proposed a framework for modeling textual data using keystroke-based features. Such methods pay attention to how a document or response was written, rather than the final text that was produced. These features are vastly different from the kind of features extracted from raw text but reveal information that is otherwise hidden. We hypothesized that pairing efficient machine learning techniques with keystroke log information should produce results comparable to transformer techniques, models which pay more or less attention to the different components of a text sequence in a far quicker time. Transformer-based methods dominate the field of NLP currently due to the strong understanding they display of natural language. We showed that models trained on keystroke log data are capable of effectively evaluating the quality of writing and do it in a significantly shorter amount of time compared to traditional methods. This is significant as it provides a necessary fast and cheap alternative to increasingly larger and slower LLMs.
Read More...Using data science along with machine learning to determine the ARIMA model’s ability to adjust to irregularities in the dataset

Auto-Regressive Integrated Moving Average (ARIMA) models are known for their influence and application on time series data. This statistical analysis model uses time series data to depict future trends or values: a key contributor to crime mapping algorithms. However, the models may not function to their true potential when analyzing data with many different patterns. In order to determine the potential of ARIMA models, our research will test the model on irregularities in the data. Our team hypothesizes that the ARIMA model will be able to adapt to the different irregularities in the data that do not correspond to a certain trend or pattern. Using crime theft data and an ARIMA model, we determined the results of the ARIMA model’s forecast and how the accuracy differed on different days with irregularities in crime.
Read More...Recognition of animal body parts via supervised learning
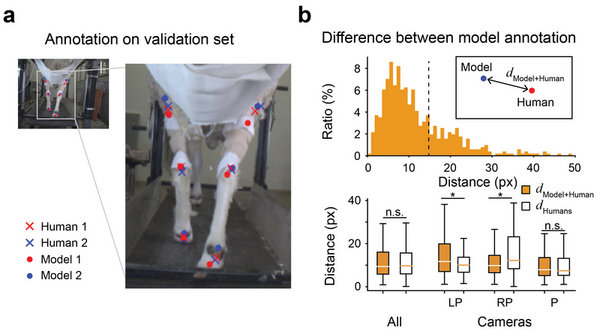
The application of machine learning techniques has facilitated the automatic annotation of behavior in video sequences, offering a promising approach for ethological studies by reducing the manual effort required for annotating each video frame. Nevertheless, before solely relying on machine-generated annotations, it is essential to evaluate the accuracy of these annotations to ensure their reliability and applicability. While it is conventionally accepted that there cannot be a perfect annotation, the degree of error associated with machine-generated annotations should be commensurate with the error between different human annotators. We hypothesized that machine learning supervised with adequate human annotations would be able to accurately predict body parts from video sequences. Here, we conducted a comparative analysis of the quality of annotations generated by humans and machines for the body parts of sheep during treadmill walking. For human annotation, two annotators manually labeled six body parts of sheep in 300 frames. To generate machine annotations, we employed the state-of-the-art pose-estimating library, DeepLabCut, which was trained using the frames annotated by human annotators. As expected, the human annotations demonstrated high consistency between annotators. Notably, the machine learning algorithm also generated accurate predictions, with errors comparable to those between humans. We also observed that abnormal annotations with a high error could be revised by introducing Kalman Filtering, which interpolates the trajectory of body parts over the time series, enhancing robustness. Our results suggest that conventional transfer learning methods can generate behavior annotations as accurate as those made by humans, presenting great potential for further research.
Read More...Sloan green and red photometry of the Type Ia supernova 2024neh

Analysis of the Sloan green and red photometry of the Type Ia supernova 2024neh
Read More...Effects of Coolant Temperature on the Characteristics of Soil Cooling Curve
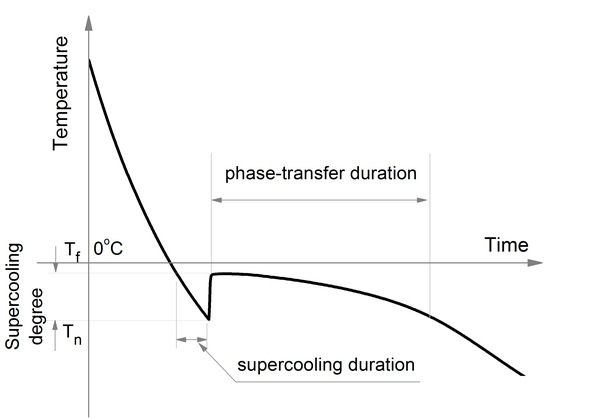
In this article, the authors investigate whether coolant temperature affects soil cooling curves of soil with otherwise identical properties. The coolant temperature is representative of environmental temperature, and the authors hypothesized that differences in this temperature would not affect the freezing temperature of soil. Their findings validated their hypothesis providing helpful information relevant to understanding how frost heaves happen and how to predict their occurrence more accurately.
Read More...Analysis of professional and amateur tennis serves using computer pose detection

The authors looked at the dynamics of tennis serves from professional and amateur athletes.
Read More...Enhanced soil fertility through seaweed-derived biochar: A comparative analysis with commercial fertilizers
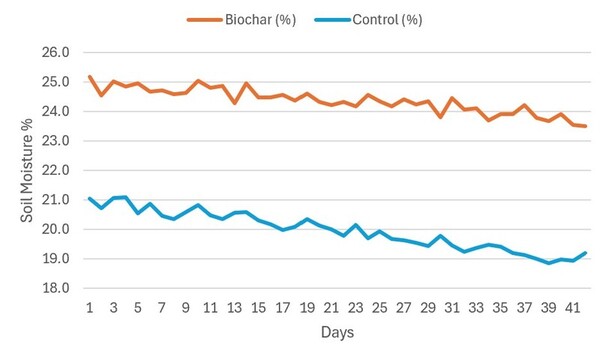
The study explored converting Gracilaria seaweed waste—known for releasing toxic hydrogen sulfide when decomposed—into biochar as a sustainable solution for waste management and soil improvement.
Read More...Stock price prediction: Long short-term memory vs. Autoformer and time series foundation model
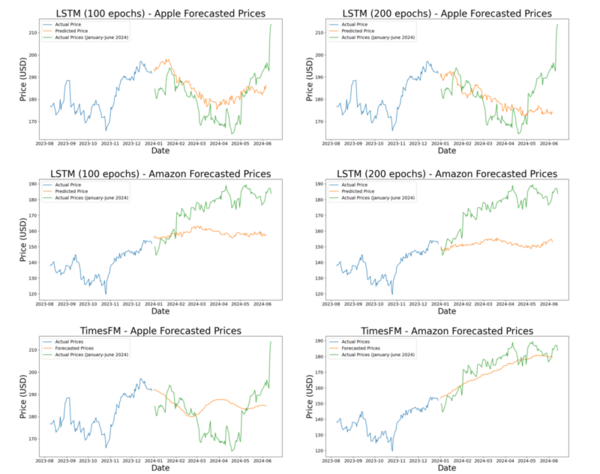
The authors looked the ability to predict future stock prices using various machine learning models.
Read More...Differential privacy in machine learning for traffic forecasting
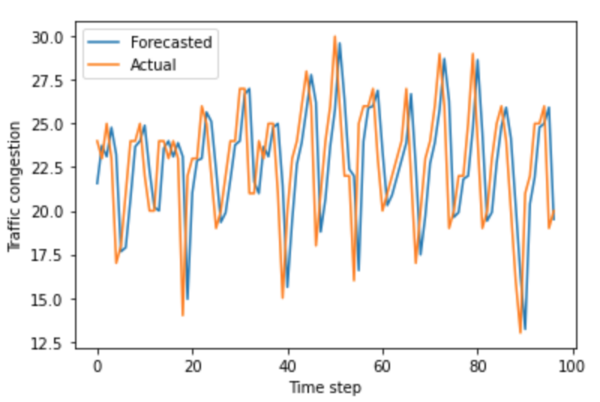
In this paper, we measured the privacy budgets and utilities of different differentially private mechanisms combined with different machine learning models that forecast traffic congestion at future timestamps. We expected the ANNs combined with the Staircase mechanism to perform the best with every value in the privacy budget range, especially with the medium high values of the privacy budget. In this study, we used the Autoregressive Integrated Moving Average (ARIMA) and neural network models to forecast and then added differentially private Laplacian, Gaussian, and Staircase noise to our datasets. We tested two real traffic congestion datasets, experimented with the different models, and examined their utility for different privacy budgets. We found that a favorable combination for this application was neural networks with the Staircase mechanism. Our findings identify the optimal models when dealing with tricky time series forecasting and can be used in non-traffic applications like disease tracking and population growth.
Read More...