Despite the prevalence of PD, diagnosing PD is expensive, requires specialized testing, and is often inaccurate. Moreover, diagnosis is often made late in the disease course when treatments are less effective. Using existing voice data from patients with PD and healthy controls, the authors created and trained two different algorithms: one using logistic regression and another employing an artificial neural network (ANN).
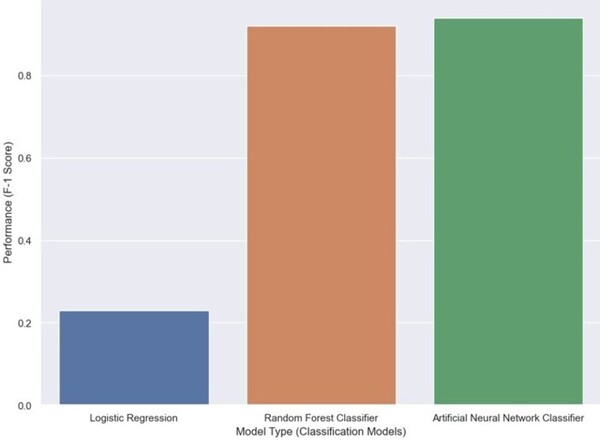
Machine learning algorithms are becoming increasingly popular for data crunching across a vast area of scientific disciplines. Here, the authors compare two machine learning algorithms with respect to accuracy and user-friendliness and find that random forest algorithms outperform logistic regression when applied to the same dataset.
Given an association between nicotine addiction and gene expression, we hypothesized that expression of genes commonly associated with smoking status would have variable expression between smokers and non-smokers. To test whether gene expression varies between smokers and non-smokers, we analyzed two publicly-available datasets that profiled RNA gene expression from brain (nucleus accumbens) and lung tissue taken from patients identified as smokers or non-smokers. We discovered statistically significant differences in expression of dozens of genes between smokers and non-smokers. To test whether gene expression can be used to predict whether a patient is a smoker or non-smoker, we used gene expression as the training data for a logistic regression or random forest classification model. The random forest classifier trained on lung tissue data showed the most robust results, with area under curve (AUC) values consistently between 0.82 and 0.93. Both models trained on nucleus accumbens data had poorer performance, with AUC values consistently between 0.65 and 0.7 when using random forest. These results suggest gene expression can be used to predict smoking status using traditional machine learning models. Additionally, based on our random forest model, we proposed KCNJ3 and TXLNGY as two candidate markers of smoking status. These findings, coupled with other genes identified in this study, present promising avenues for advancing applications related to the genetic foundation of smoking-related characteristics.
Machine learning and deep learning techniques can be used to predict the early onset of breast cancer. The main objective of this analysis was to determine whether machine learning algorithms can be used to predict the onset of breast cancer with more than 90% accuracy. Based on research with supervised machine learning algorithms, Gaussian Naïve Bayes, K Nearest Algorithm, Random Forest, and Logistic Regression were considered because they offer a wide variety of classification methods and also provide high accuracy and performance. We hypothesized that all these algorithms would provide accurate results, and Random Forest and Logistic Regression would provide better accuracy and performance than Naïve Bayes and K Nearest Neighbor.
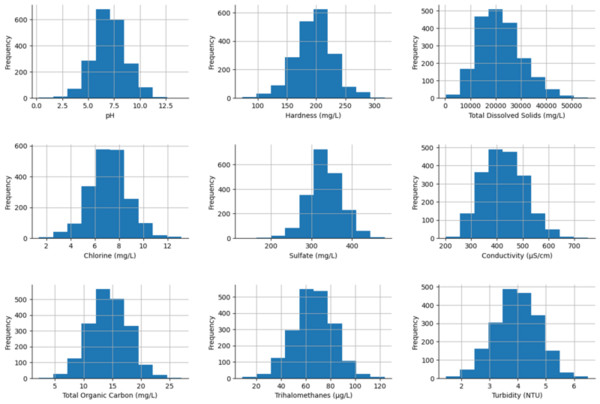
The global issue of water quality has led to the use of machine learning models, like ANN and SVM, to predict water potability. However, these models can be complex and resource-intensive. This research aimed to find a simpler, more efficient model for water quality prediction.
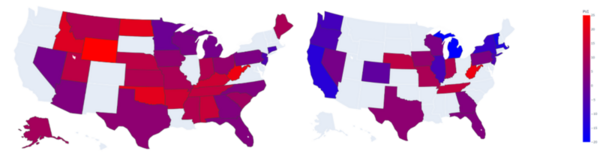
The authors analyze political endorsement patterns and impacts from the 2018 and 2020 midterm elections and find that such endorsements may be predictable based on the ideological and demographic factors of the endorser.
The authors combine fine needle aspiration biopsy and machine learning algorithms to develop a breast cancer detection method suitable for resource-constrained regions that lack access to mammograms.