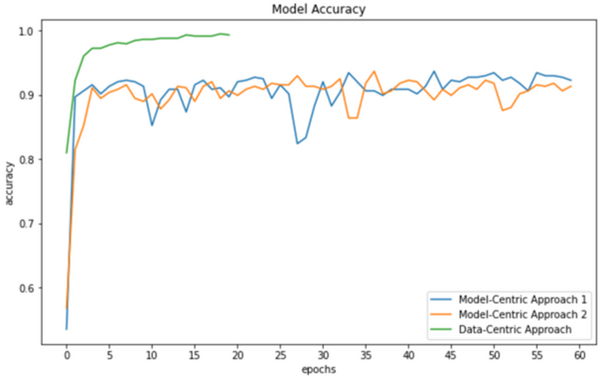
In this study, three models are used to test the hypothesis that data-centric artificial intelligence (AI) will improve the performance of machine learning.
Read More...Comparing model-centric and data-centric approaches to determine the efficiency of data-centric AI
In this study, three models are used to test the hypothesis that data-centric artificial intelligence (AI) will improve the performance of machine learning.
Read More...A Data-Centric Analysis of “Stop and Frisk” in New York City

The death of George Floyd has shed light on the disproportionate level of policing affecting non-Whites in the United States of America. To explore whether non-Whites were disproportionately targetted by New York City's "Stop and Frisk" policy, the authors analyze publicly available data on the practice between 2003-2019. Their results suggest African Americans were indeed more likely to be stopped by the police until 2012, after which there was some improvement.
Read More...A machine learning approach for abstraction and reasoning problems without large amounts of data

While remarkable in its ability to mirror human cognition, machine learning and its associated algorithms often require extensive data to prove effective in completing tasks. However, data is not always plentiful, with unpredictable events occurring throughout our daily lives that require flexibility by artificial intelligence utilized in technology such as personal assistants and self-driving vehicles. Driven by the need for AI to complete tasks without extensive training, the researchers in this article use fluid intelligence assessments to develop an algorithm capable of generalization and abstraction. By forgoing prioritization on skill-based training, this article demonstrates the potential of focusing on a more generalized cognitive ability for artificial intelligence, proving more flexible and thus human-like in solving unique tasks than skill-focused algorithms.
Read More...Comparative data analysis on the effect of socioeconomic factors on math proficiency
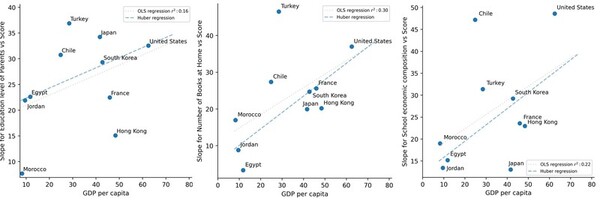
This study examines how socioeconomic status (SES) influences student mathematics achievement across countries by conducting multiple regression analyses to the Trends in International Mathematics and Science Study (TIMSS) 2019 dataset.
Read More...Optimizing data augmentation to improve machine learning accuracy on endemic frog calls

The mountain chain of the Western Ghats on the Indian peninsula, a UNESCO World Heritage site, is home to about 200 frog species, 89 of which are endemic. Distinctive to each frog species, their vocalizations can be used for species recognition. Manually surveying frogs at night during the rain in elephant and big cat forests is difficult, so being able to autonomously record ambient soundscapes and identify species is essential. An effective machine learning (ML) species classifier requires substantial training data from this area. The goal of this study was to assess data augmentation techniques on a dataset of frog vocalizations from this region, which has a minimal number of audio recordings per species. Consequently, enhancing an ML model’s performance with limited data is necessary. We analyzed the effects of four data augmentation techniques (Time Shifting, Noise Injection, Spectral Augmentation, and Test-Time Augmentation) individually and their combined effect on the frog vocalization data and the public environmental sounds dataset (ESC-50). The effect of combined data augmentation techniques improved the model's relative accuracy as the size of the dataset decreased. The combination of all four techniques improved the ML model’s classification accuracy on the frog calls dataset by 94%. This study established a data augmentation approach to maximize the classification accuracy with sparse data of frog call recordings, thereby creating a possibility to build a real-world automated field frog species identifier system. Such a system can significantly help in the conservation of frog species in this vital biodiversity hotspot.
Read More...Using data science along with machine learning to determine the ARIMA model’s ability to adjust to irregularities in the dataset

Auto-Regressive Integrated Moving Average (ARIMA) models are known for their influence and application on time series data. This statistical analysis model uses time series data to depict future trends or values: a key contributor to crime mapping algorithms. However, the models may not function to their true potential when analyzing data with many different patterns. In order to determine the potential of ARIMA models, our research will test the model on irregularities in the data. Our team hypothesizes that the ARIMA model will be able to adapt to the different irregularities in the data that do not correspond to a certain trend or pattern. Using crime theft data and an ARIMA model, we determined the results of the ARIMA model’s forecast and how the accuracy differed on different days with irregularities in crime.
Read More...Using satellite surface temperature data to monitor urban heat island

This manuscript investigates the urban heat island (UHI) effect by utilizing two satellite datasets: Landsat (high spatial resolution, lower temporal resolution) and MODIS (lower spatial resolution, high temporal resolution). The authors hypothesized that Landsat would provide better spatial detail, while MODIS would better capture temporal variations. Their analysis in the Washington D.C.–Baltimore region supports these hypotheses, demonstrating that Landsat offers finer spatial details, whereas MODIS provides more consistent seasonal patterns and better detects heatwave frequencies.
Read More...Optimizing tennis strategy: a data-driven analysis of point importance

The authors looked at the importance of different point breakdowns needed to win in a game of tennis.
Read More...Effects of data amount and variation in deep learning-based tuberculosis diagnosis in chest X-ray scans
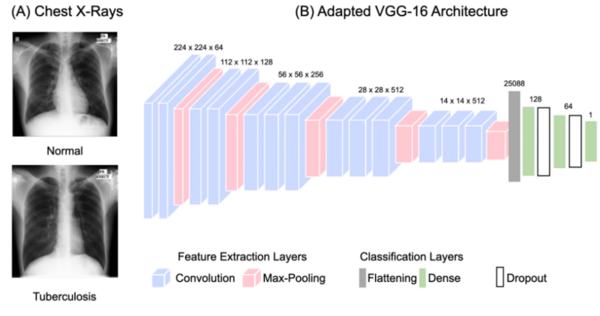
The authors developed and tested machine learning methods to diagnose tuberculosis from pulmonary X-ray scans.
Read More...Epileptic seizure detection using machine learning on electroencephalogram data
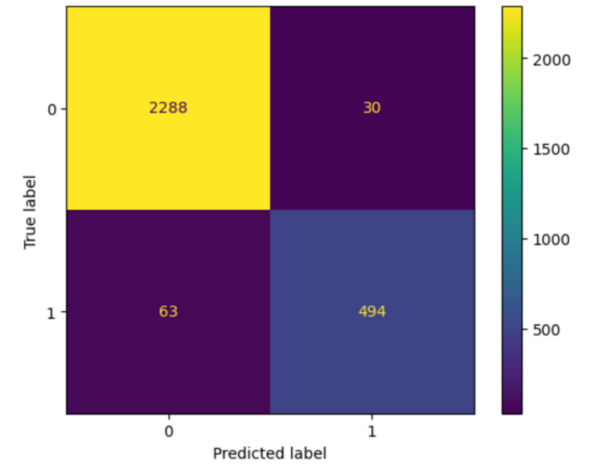
The authors use machine learning and electroencephalogram data to propose a method for improving epilepsy diagnosis.
Read More...