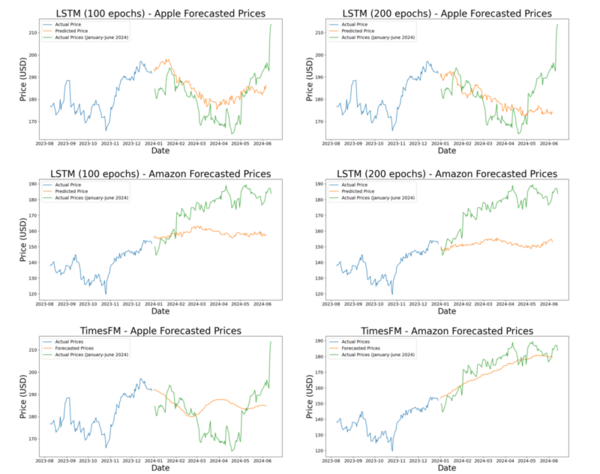
The authors looked the ability to predict future stock prices using various machine learning models.
Read More...Stock price prediction: Long short-term memory vs. Autoformer and time series foundation model
The authors looked the ability to predict future stock prices using various machine learning models.
Read More...Mitigating open-set misclassification in a colorectal cancer detecting neural network
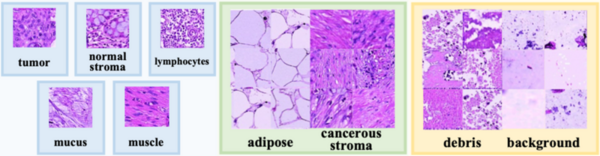
The authors develop a machine learning method to reduce misclassification of objects in safety-critical applications such as medical diagnosis.
Read More...The utilization of Artificial Intelligence in enabling the early detection of brain tumors
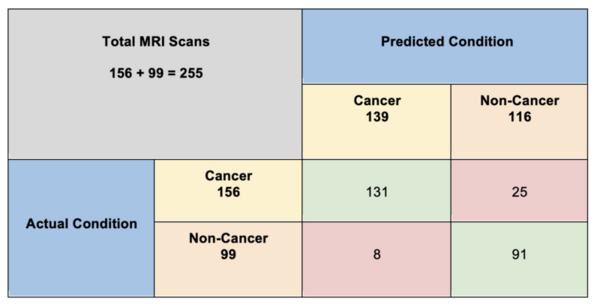
AI analysis of brain scans offers promise for helping doctors diagnose brain tumors. Haider and Drosis explore this field by developing machine learning models that classify brain scans as "cancer" or "non-cancer" diagnoses.
Read More...Using neural networks to detect and categorize sounds

The authors test different machine learning algorithms to remove background noise from audio to help people with hearing loss differentiate between important sounds and distracting noise.
Read More...Prediction of diabetes using supervised classification
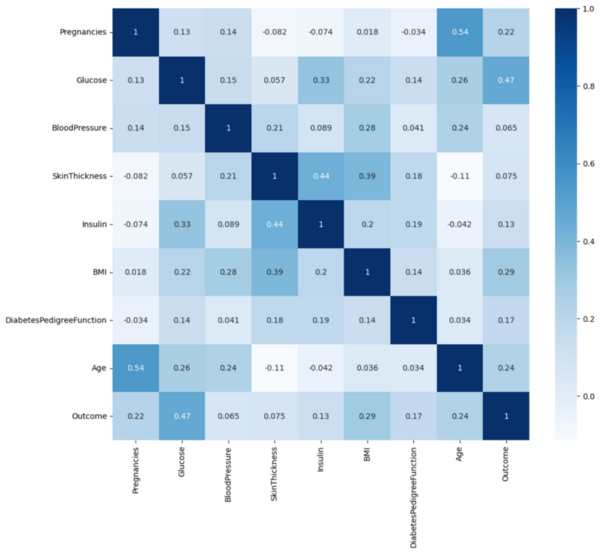
The authors develop and test a machine learning algorithm for predicting diabetes diagnoses.
Read More...Predicting baseball pitcher efficacy using physical pitch characteristics

Here, the authors sought to develop a new metric to evaluate the efficacy of baseball pitchers using machine learning models. They found that the frequency of balls, was the most predictive feature for their walks/hits allowed per inning (WHIP) metric. While their machine learning models did not identify a defining trait, such as high velocity, spin rate, or types of pitches, they found that consistently pitching within the strike zone resulted in significantly lower WHIPs.
Read More...Model selection and optimization for poverty prediction on household data from Cambodia

Here the authors sought to use three machine learning models to predict poverty levels in Cambodia based on available household data. They found teat multilayer perceptron outperformed the other models, with an accuracy of 87 %. They suggest that data-driven approaches such as these could be used more effectively target and alleviate poverty.
Read More...An explainable model for content moderation
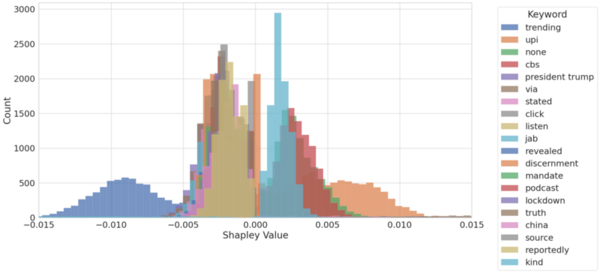
The authors looked at the ability of machine learning algorithms to interpret language given their increasing use in moderating content on social media. Using an explainable model they were able to achieve 81% accuracy in detecting fake vs. real news based on language of posts alone.
Read More...Evaluating the feasibility of SMILES-based autoencoders for drug discovery
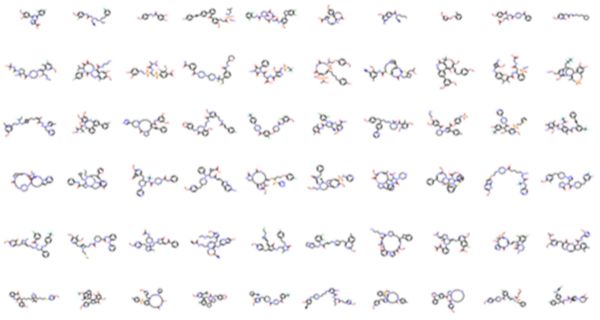
The authors investigate the ability of machine learning models to developing new drug-like molecules by learning desired chemical properties versus simply generating molecules that similar to those in the training set.
Read More...Comparing model-centric and data-centric approaches to determine the efficiency of data-centric AI
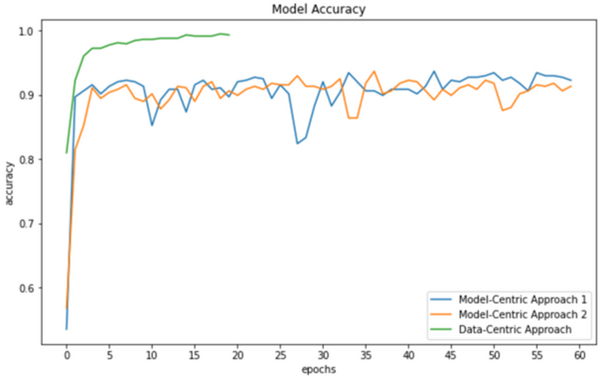
In this study, three models are used to test the hypothesis that data-centric artificial intelligence (AI) will improve the performance of machine learning.
Read More...