
In this article, the authors identify the characteristics that make a book a best-seller. Knowing what, besides content, predicts the success of a book can help publishers maximize the success of their print products.
Read More...A Novel Model to Predict a Book's Success in the New York Times Best Sellers List
In this article, the authors identify the characteristics that make a book a best-seller. Knowing what, besides content, predicts the success of a book can help publishers maximize the success of their print products.
Read More...Monitoring drought using explainable statistical machine learning models
Droughts have a wide range of effects, from ecosystems failing and crops dying, to increased illness and decreased water quality. Drought prediction is important because it can help communities, businesses, and governments plan and prepare for these detrimental effects. This study predicts drought conditions by using predictable weather patterns in machine learning models.
Read More...SmartZoo: A Deep Learning Framework for an IoT Platform in Animal Care
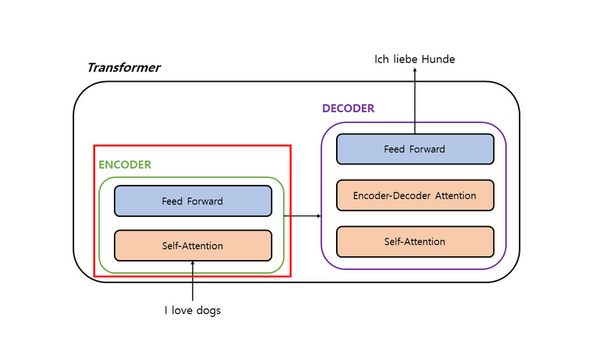
Zoos offer educational and scientific advantages but face high maintenance costs and challenges in animal care due to diverse species' habits. Challenges include tracking animals, detecting illnesses, and creating suitable habitats. We developed a deep learning framework called SmartZoo to address these issues and enable efficient animal monitoring, condition alerts, and data aggregation. We discovered that the data generated by our model is closer to real data than random data, and we were able to demonstrate that the model excels at generating data that resembles real-world data.
Read More...Comparison of three large language models as middle school math tutoring assistants

Middle school math forms the basis for advanced mathematical courses leading up to the university level. Large language models (LLMs) have the potential to power next-generation educational technologies, acting as digital tutors to students. The main objective of this study was to determine whether LLMs like ChatGPT, Bard, and Llama 2 can serve as reliable middle school math tutoring assistants on three tutoring tasks: hint generation, comprehensive solution, and exercise creation.
Read More...Automated classification of nebulae using deep learning & machine learning for enhanced discovery
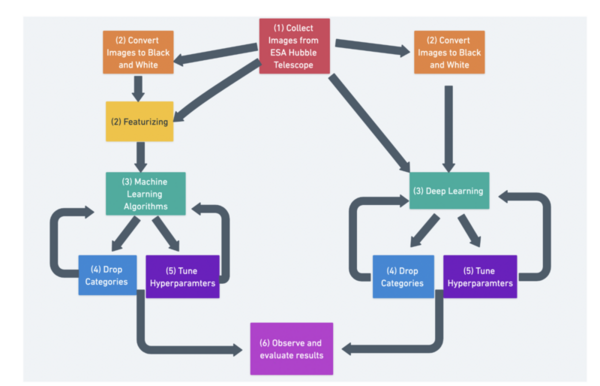
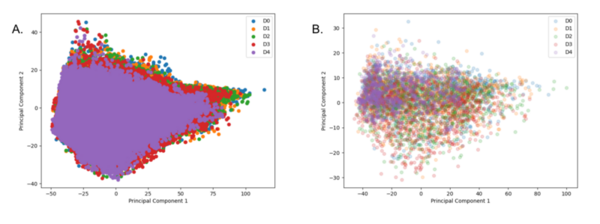
There are believed to be ~20,000 nebulae in the Milky Way Galaxy. However, humans have only cataloged ~1,800 of them even though we have gathered 1.3 million nebula images. Classification of nebulae is important as it helps scientists understand the chemical composition of a nebula which in turn helps them understand the material of the original star. Our research on nebulae classification aims to make the process of classifying new nebulae faster and more accurate using a hybrid of deep learning and machine learning techniques.
Read More...Optimizing Interplanetary Travel Using a Genetic Algorithm

In this work, the authors develop an algorithm that solves the problem of efficient space travel between planets. This is a problem that could soon be of relevance as mankind continues to expand its exploration of outer space, and potentially attempt to inhabit it.
Read More...Analysis of quantitative classification and properties of X-ray binary systems
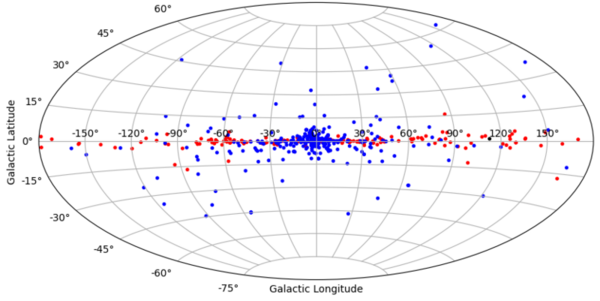
The authors looked at variables and their patterns and how those contribute to the properties of X-ray binaries.
Read More...Levering machine learning to distinguish between optimal and suboptimal basketball shooting forms

The authors looked at different ways to build computational resources that would analyze shooting form for basketball players.
Read More...Optimizing data augmentation to improve machine learning accuracy on endemic frog calls

The mountain chain of the Western Ghats on the Indian peninsula, a UNESCO World Heritage site, is home to about 200 frog species, 89 of which are endemic. Distinctive to each frog species, their vocalizations can be used for species recognition. Manually surveying frogs at night during the rain in elephant and big cat forests is difficult, so being able to autonomously record ambient soundscapes and identify species is essential. An effective machine learning (ML) species classifier requires substantial training data from this area. The goal of this study was to assess data augmentation techniques on a dataset of frog vocalizations from this region, which has a minimal number of audio recordings per species. Consequently, enhancing an ML model’s performance with limited data is necessary. We analyzed the effects of four data augmentation techniques (Time Shifting, Noise Injection, Spectral Augmentation, and Test-Time Augmentation) individually and their combined effect on the frog vocalization data and the public environmental sounds dataset (ESC-50). The effect of combined data augmentation techniques improved the model's relative accuracy as the size of the dataset decreased. The combination of all four techniques improved the ML model’s classification accuracy on the frog calls dataset by 94%. This study established a data augmentation approach to maximize the classification accuracy with sparse data of frog call recordings, thereby creating a possibility to build a real-world automated field frog species identifier system. Such a system can significantly help in the conservation of frog species in this vital biodiversity hotspot.
Read More...Effects of different synthetic training data on real test data for semantic segmentation

Semantic segmentation - labelling each pixel in an image to a specific class- models require large amounts of manually labeled and collected data to train.
Read More...