Building a video classifier to improve the accuracy of depth-aware frame interpolation
(1) Saint Francis High School, Mountain View, California, (2) Torrey Pines High School, San Diego, California, (3) University of California, Santa Barbara, Santa Barbara, California
https://doi.org/10.59720/20-227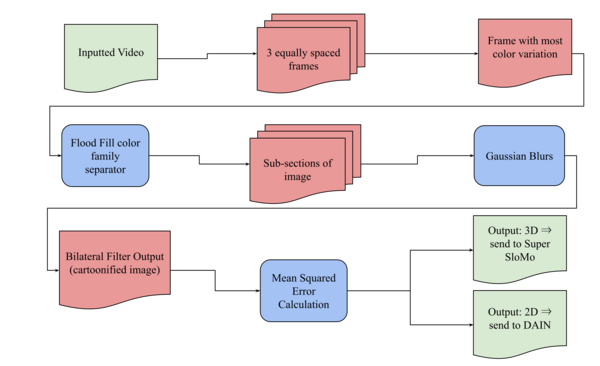
With the current growth in video technology, 4K resolution and sixty frames per second are becoming the industry standards for live, pre-recorded, and animated footage. Although many old movies have a lower frame rate because of insufficient technology, the larger issue lies in the processing of videos. As videos are streamed online, the frame rate can be significantly impaired. So, if we can computationally increase the frame rate, we can dramatically reduce the amount of data being sent to the user. With the recent rising popularity, efficiency, and effectiveness of artificial intelligence, deep learning is undoubtedly the most plausible solution to this problem. Multiple projects have used neural networks to interpolate videos and improve their frame rate. However, since different categories of videos, such as two-dimensional and three-dimensional, can have drastically different color schemes and motion paths, training a single model to handle all of them leads to overfitting, which can be seen in current interpolation algorithms that are specialized to interpolate certain categories of videos. To combat this issue, we researched whether it would be possible to find a single method to perform frame interpolation invariant to the type of video inputted. In this process, we found several pre-existing models that performed well with either 2D or 3D footage, but not both; therefore, we hypothesized that building a video classifier to categorize the input video’s dimensionality would thus improve their accuracy. After integrating the classifier with two depth-aware frame interpolation models, we improved the average accuracy to 97.2%.
This article has been tagged with: