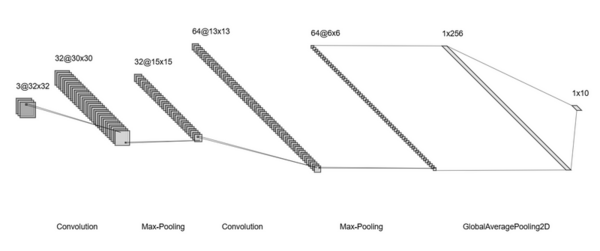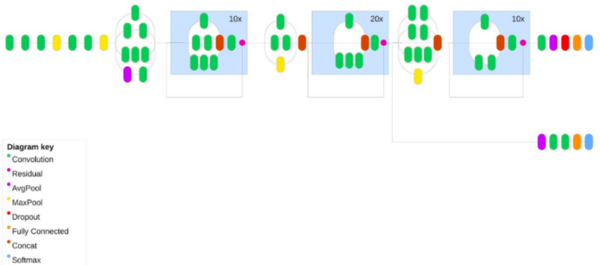
This article discusses Alopecia areata, an autoimmune disorder causing sudden hair loss due to the immune system mistakenly attacking hair follicles. The article introduces the use of deep learning (DL) techniques, particularly convolutional neural networks (CNN), for classifying images of healthy and alopecia-affected hair. The study presents a comparative analysis of newly optimized CNN models with existing ones, trained on datasets containing images of healthy and alopecia-affected hair. The Inception-Resnet-v2 model emerged as the most effective for classifying Alopecia Areata.
Read More...