
The authors developed a quantum inspired model for stock market fluctuations.
Read More...Quantum-inspired neural networks enhance stock prediction accuracy
The authors developed a quantum inspired model for stock market fluctuations.
Read More...Towards multimodal longitudinal analysis for predicting cognitive decline

Understanding and predicting cognitive decline in Alzheimer's disease
Read More...Advancing pediatric cancer predictions through generative artificial intelligence and machine learning
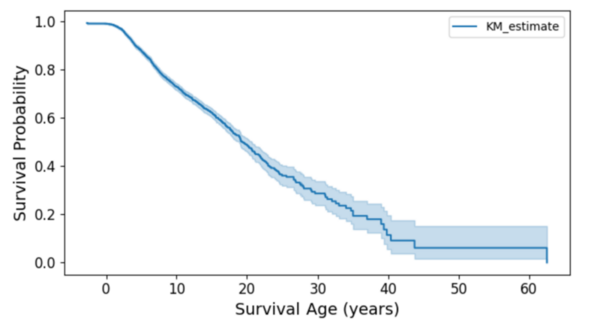
Pediatric cancers pose unique challenges due to their rarity and distinct biological factors, emphasizing the need for accurate survival prediction to guide treatment. This study integrated generative AI and machine learning, including synthetic data, to analyze 9,184 pediatric cancer patients, identifying age at diagnosis, cancer types, and anatomical sites as significant survival predictors. The findings highlight the potential of AI-driven approaches to improve survival prediction and inform personalized treatment strategies, with broader implications for innovative healthcare applications.
Read More...Weather-based power outage prediction in New York City: An ensemble machine learning approach

This study contributes to our understanding of how urban energy systems respond to climate variability and inform strategies for enhancing power grid resilience. The findings can help inform urban planners and infrastructure developers by identifying the factors that make regions within a power grid more vulnerable.
Read More...Predicting sickle cell vaso-occlusion by microscopic imaging and modeling
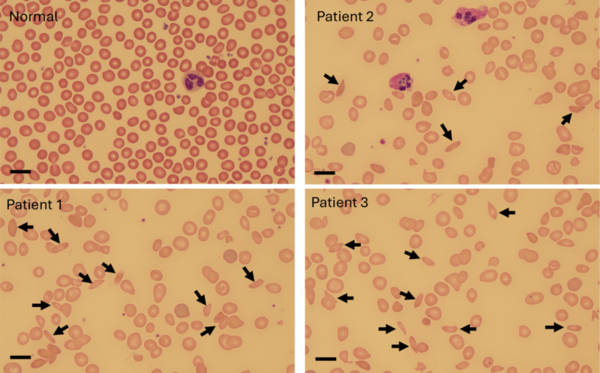
The authors use blood smears from individuals with sickle cell disease to correlate sickle cell frequency with the occurrence of vaso-occlusive crises.
Read More...Simple solving heuristics improve the accuracy of sudoku difficulty classifiers
Building deep neural networks to detect candy from photos and estimate nutrient portfolio

The authors use pictures of candy wrappers and neural networks to improve nutritional accuracy of diet-tracking apps.
Read More...Developing a neural network to model the mechanical properties of 13-8 PH stainless steel alloy

We systematically evaluated the effects of raw material composition, heat treatment, and mechanical properties on 13-8PH stainless steel alloy. The results of the neural network models were in agreement with experimental results and aided in the evaluation of the effects of aging temperature on double shear strength. The data suggests that this model can be used to determine the appropriate 13-8PH alloy aging temperature needed to achieve the desired mechanical properties, eliminating the need for many costly trials and errors through re-heat treatments.
Read More...Contrasting role of ASCC3 and ALKBH3 in determining genomic alterations in Glioblastoma Multiforme
Glioblastoma Multiforme (GBM) is the most malignant brain tumor with the highest fraction of genome alterations (FGA), manifesting poor disease-free status (DFS) and overall survival (OS). We explored The Cancer Genome Atlas (TCGA) and cBioportal public dataset- Firehose legacy GBM to study DNA repair genes Activating Signal Cointegrator 1 Complex Subunit 3 (ASCC3) and Alpha-Ketoglutarate-Dependent Dioxygenase AlkB Homolog 3 (ALKBH3). To test our hypothesis that these genes have correlations with FGA and can better determine prognosis and survival, we sorted the dataset to arrive at 254 patients. Analyzing using RStudio, both ASCC3 and ALKBH3 demonstrated hypomethylation in 82.3% and 61.8% of patients, respectively. Interestingly, low mRNA expression was observed in both these genes. We further conducted correlation tests between both methylation and mRNA expression of these genes with FGA. ASCC3 was found to be negatively correlated, while ALKBH3 was found to be positively correlated, potentially indicating contrasting dysregulation of these two genes. Prognostic analysis showed the following: ASCC3 hypomethylation is significant with DFS and high ASCC3 mRNA expression to be significant with OS, demonstrating ASCC3’s potential as disease prediction marker.
Read More...Risk assessment modeling for childhood stunting using automated machine learning and demographic analysis
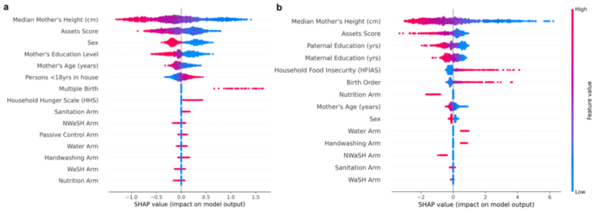
Over the last few decades, childhood stunting has persisted as a major global challenge. This study hypothesized that TPTO (Tree-based Pipeline Optimization Tool), an AutoML (automated machine learning) tool, would outperform all pre-existing machine learning models and reveal the positive impact of economic prosperity, strong familial traits, and resource attainability on reducing stunting risk. Feature correlation plots revealed that maternal height, wealth indicators, and parental education were universally important features for determining stunting outcomes approximately two years after birth. These results help inform future research by highlighting how demographic, familial, and socio-economic conditions influence stunting and providing medical professionals with a deployable risk assessment tool for predicting childhood stunting.
Read More...